Пусть Omega\Omega - множество элементов, которые называются элементарными исходами или элементарными событиями. Непустой класс A\mathcal{A} подмножеств из Omega\Omega, замкнутый относительно операции дополнения и операций объединения конечного и счетного числа своих подмножеств, называется sigma\sigma-алгеброй на Omega\Omega, а сами подмножества - событиями. Приведенные ниже два тождества
(nnn_(j in I)A_(j))^(C)=uuu_(j in I)A_(j)^(C)" и "(uuu_(j in I)A_(j))^(C)=nnn_(j in I)A_(j)^(C),\left(\bigcap_{j \in I} A_{j}\right)^{C}=\bigcup_{j \in I} A_{j}^{C} \text { и }\left(\bigcup_{j \in I} A_{j}\right)^{C}=\bigcap_{j \in I} A_{j}^{C},
в которых буква II обозначает произвольное множество индексов, называются формулами двойственности. Используя первое тождество, можно показать, что sigma\sigma-алгебра замкнута также относительно конечных и счетных пересечений. Если AA - событие, то его дополнение A^(C)A^{C} также является событием. Поэтому все множество Omega=A uuA^(C)\Omega=A \cup A^{C}, а также пустое подмножество O/=A nnA^(C)\emptyset=A \cap A^{C} также являются событиями. Они называются достоверным и невозможным событиями соответственно. Легко убедиться непосредственной проверкой, что
минимальная sigma\sigma-алгебра, содержащая событие AA, состоит из четырех подмножеств {O/,A,A^(C),Omega}\left\{\varnothing, A, A^{C}, \Omega\right\}. В качестве другого очевидного примера sigma\sigma-алгебры можно указать множество всех подмножеств Omega\Omega. Обычно именно такие sigma\sigma-алгебры используются в тех случаях, когда множество Omega\Omega является конечным или счетным. Пару, состоящую из множества Omega\Omega элементарных исходов и sigma\sigma-алгебры A\mathcal{A} его подмножеств, принято называть измеримым пространством (Omega,A)(\Omega, \mathcal{A}).
Пусть KK - произвольное множество индексов, (B_(k))_(k in K)\left(B_{k}\right)_{k \in K} - непустое семейство подмножеств из Omega\Omega, а A(B_(k),k in K)\mathcal{A}\left(B_{k}, k \in K\right) - пересечение всех sigma\sigma-алгебр, содержащих это семейство. Одной из таких sigma\sigma-алгебр является sigma\sigma-алгебра всех подмножеств Omega\Omega. Очевидно, что (B_(k))_(k in K)\left(B_{k}\right)_{k \in K} принадлежит этому пересечению, которое также является sigma\sigma-алгеброй. Эта sigma\sigma-алгебра называется sigma\sigma-алгеброй, порожденной семейством (B_(k))_(k in K)\left(B_{k}\right)_{k \in K}, и является наименьшей sigma\sigma-алгеброй, содержащей это семейство. В частности, приведенная выше sigma\sigma-алгебра {O/,A,A^(C),Omega}\left\{\varnothing, A, A^{C}, \Omega\right\} является наименьшей sigma\sigma-алгеброй A(A)\mathcal{A}(A), порожденной подмножеством A in OmegaA \in \Omega.
Пример sigma\sigma-алгебры ...
Далее будет часто использоваться sigma\sigma-алгебра, порожденная всеми интервалами вещественной прямой RR. Она называется борелевской sigma\sigma-алгеброй и обозначается символом B.sigma\mathcal{B} . \sigma-Алгебра, порожденная vv-мерными интервалами из R^(v)R^{\boldsymbol{v}}, которые называются также гиперинтервалами или гиперпараллелепипедами, также называется борелевской и обозначается символом B^(v)\mathcal{B}^{v}. Ниже приводятся примеры подмножеств sigma\sigma-алгебры B\mathcal{B}, которые называются борелевскими множествами на прямой RR.
(1.1.1) Каждая точка aa прямой RR является борелевским подмножеством, состоящим из одного элемента. Это следует из того, что любая точка a in Ra \in R есть счетное пересечение открытых интервалов
открытых интервалов, которые являются борелевскими подмножествами.
(1.1.2) Множество QQ точек с рациональными координатами является борелевским, так как оно есть объединение счетного числа таких точек.
(1.1.3) Множество иррациональных точек является борелевским, так как оно есть дополнение Q^(c)=R\\QQ^{c}=R \backslash Q множества рациональных чисел.
(1.1.4) Любое открытое множество на RR является борелевским, так как оно есть объединение конечного или счетного числа попарно пересекающихся своих открытых интервалов.
(1.1.5) Замкнутое множество является борелевским, так как оно есть дополнение открытого множества.
(1.1.6) Если отображение f:[0,1]rarr Rf:[0,1] \rightarrow R - непрерывно, то при любом c in Rc \in R множество {x in[0,1]:f(x) <= c}\{x \in[0,1]: f(x) \leq c\} является замкнутым, а значит борелевским.
Вероятностью на sigma\sigma-алгебре A\mathcal{A} называется отображение P:Ararr RP: \mathcal{A} \rightarrow R, удовлетворяющее трем аксиомам. Во-первых, отображение PP является неотрицательным: P(A) >= 0P(A) \geq 0 для любого A inAA \in \mathcal{A}. Во-вторых, отображение PP является нормированным: P(Omega)=1P(\Omega)=1. Наконец, отображение PP является счетно-аддитивным отображением. Последнее свойство означает, что для любого конечного или счетного семейства (A_(k))_(k in K)\left(A_{k}\right)_{k \in K} попарно непересекающихся подмножеств из A\mathcal{A} имеет место равенство
P(sum_(k in K)A_(k))=sum_(k in K)P(A_(k)).P\left(\sum_{k \in K} A_{k}\right)=\sum_{k \in K} P\left(A_{k}\right) .
Совокупность, состоящая из множества элементарных исходов Omega,sigma\Omega, \sigma-алгебры событий A\mathcal{A} и вероятности PP на A\mathcal{A}, называется вероятностным пространством и обозначается ( Omega,A,P\Omega, \mathcal{A}, P ).
(1.1.7) Вероятностное пространство с конечным множеством элементарных исходов. Далее для обозначения количества элементов конечного множества Omega\Omega будет использоваться символ |Omega||\Omega|. Если |Omega| < +oo|\Omega|<+\infty, то в качестве sigma\sigma-алгебры A\mathcal{A} обычно используют множество всех подмножеств Omega\Omega. Всегда можно поставить в соответствие каждому элементарному исходу omega in Omega\omega \in \Omega неотрицательное число P({omega}) >= 0P(\{\omega\}) \geq 0 такое, что
sum_(omega in Omega)P({omega})=1\sum_{\omega \in \Omega} P(\{\omega\})=1
В самом деле, пусть n=|Omega|n=|\Omega|. Перенумеруем элементы Omega\Omega, выберем в интервале ]0,1[:}] 0,1\left[\right. точки (x_(j))_(1 <= j <= n-1)\left(x_{j}\right)_{1 \leq j \leq n-1} таким образом, чтобы x_(1) <= x_(2) <= cdots <= x_(n-1)x_{1} \leq x_{2} \leq \cdots \leq x_{n-1} и определим nn чисел (p_(j))_(1 <= j <= n)\left(p_{j}\right)_{1 \leq j \leq n} следующим образом
Нетрудно убедиться в том, что p_(1)+,,,+p_(n)=1p_{1}+,,,+p_{n}=1.
Для любого подмножества B sub OmegaB \subset \Omega, которое по определению является событием из A\mathcal{A}, определим число P(B)P(B) равенством
P(B)=sum_(omega in B)P({omega}).P(B)=\sum_{\omega \in B} P(\{\omega\}) .
Легко показать, что для так определенного отображения P:Ararr RP: \mathcal{A} \rightarrow R выполняются все аксиомы, то есть PP является вероятностью на A\mathcal{A}.
Пусть PP - вероятность на A\mathcal{A} и D inAD \in \mathcal{A}. Легко убедиться в том, что семейство A_(D)\mathcal{A}_{D}, состоящее из всех пересечений вида A nn DA \cap D, гле A inAA \in \mathcal{A}, будет sigma\sigma-алгеброй подмножеств из DD. При P(D) > 0P(D)>0 отображение P_(D):A_(D)rarr RP_{D}: \mathcal{A}_{D} \rightarrow R, определяемое для любого A nn D inA_(D)A \cap D \in \mathcal{A}_{D} равенством
P_(D)(A nn D)=(P(A nn D))/(P(D)),P_{D}(A \cap D)=\frac{P(A \cap D)}{P(D)},
будет вероятностью на A_(D)\mathcal{A}_{D}. Таким образом, совокупность ( D,A_(D),P_(D)D, \mathcal{A}_{D}, P_{D} ) является вероятностным пространством. При этом каждое событие A nn DA \cap D из A_(D)\mathcal{A}_{D} является событием в A\mathcal{A}. Поэтому вероятностное пространство ( D,A_(D),P_(D)D, \mathcal{A}_{D}, P_{D} ) называется подпространством пространства ( Omega,A,P\Omega, \mathcal{A}, P ).
Так как каждое подмножество B=A nn DB=A \cap D из A_(D)\mathcal{A}_{D} является подмножеством sigma\sigma-алгебры A\mathcal{A} и одновременно B sub DB \subset D, то вероятность P_(D)(B)P_{D}(B) можно записать следующим образом:
P_(D)(B)=(P(B))/(P(D))=(P(A nn D))/(P(D))=P(A∣D).P_{D}(B)=\frac{P(B)}{P(D)}=\frac{P(A \cap D)}{P(D)}=P(A \mid D) .
Задачи
Пусть XX - непустое множество, (A_(j))_(j in J)\left(A_{j}\right)_{j \in J} - произвольное семейство его подмножеств. Непосредственной проверкой убедиться в справедливости тождеств
(uuu_(j in J)A_(j))^(C)=nnn_(j in J)A_(j)^(C)" и "(nnn_(j in J)A_(j))^(C)=uuu_(j in J)A_(j)^(C),\left(\bigcup_{j \in J} A_{j}\right)^{C}=\bigcap_{j \in J} A_{j}^{C} \text { и }\left(\bigcap_{j \in J} A_{j}\right)^{C}=\bigcup_{j \in J} A_{j}^{C},
известных под именем формул двойственности.
2. Пусть XX и YY - непустые множества, ff - отображение вида X rarr YX \rightarrow Y, а Theta\Theta - множество, элементы которого называются индексами. Показать, что при любом B sub YB \subset Y и B_(theta)sub Y,theta in ThetaB_{\theta} \subset Y, \theta \in \Theta, справедливы тождества
{:[f^(-1)(B^(C))=(f^(-1)(B))^(C)","quadf^(-1)(uuu_(theta in Theta)B_(theta))=uuu_(theta in Theta)f^(-1)(B_(theta))],[f^(-1)(nnn_(theta in Theta)B_(theta))=nnn_(theta in Theta)f^(-1)(B_(theta))]:}\begin{gathered}
f^{-1}\left(B^{C}\right)=\left(f^{-1}(B)\right)^{C}, \quad f^{-1}\left(\bigcup_{\theta \in \Theta} B_{\theta}\right)=\bigcup_{\theta \in \Theta} f^{-1}\left(B_{\theta}\right) \\
f^{-1}\left(\bigcap_{\theta \in \Theta} B_{\theta}\right)=\bigcap_{\theta \in \Theta} f^{-1}\left(B_{\theta}\right)
\end{gathered}
Доказать, что sigma\sigma-алгебра, порожденная интервалами вида ]-oo,x],x in R]-\infty, x], x \in R, вещественной прямой RR, является борелевской.
Привести пример вероятностного пространства с конечным множеством Omega\Omega элементарных событий.
Привести пример вероятностного пространства со счетным множеством Omega\Omega элементарных событий.
Привести пример вероятностного пространства с множеством элементарных событий Omega=[0;1]xx[0;1]\Omega=[0 ; 1] \times[0 ; 1].
1.2 Случайные величины и их распределения
Операция взятия прообраза и ее свойства. Скалярные и векторные случайные величины. Примеры случайных величин. Свойства распределения векторных случайных величин. Дискретные случайные величины. Плотность распределения. Примеры. Числовые характеристики случайных величин.
Пусть (Omega,A)(\Omega, \mathcal{A}) - измеримом пространство, B\mathcal{B} - борелевская sigma\sigma - алгебра на RR. Отображение вида xi:Omega rarr R\xi: \Omega \rightarrow R называется скалярной случайной величиной, определенной на ( Omega,A\Omega, \mathcal{A} ), если для любого борелевского множества B inBB \in \mathcal{B} его прообраз
{:xi^(-1)(B)={omega in Omega:xi(omega)in B)}\left.\xi^{-1}(B)=\{\omega \in \Omega: \xi(\omega) \in B)\right\}
является событием из A\mathcal{A}.
(1.2.1) Множество C\mathcal{C} всех подмножеств BB из RR, прообразы xi^(-1)(B)\xi^{-1}(B) которых являются событиями, есть sigma\sigma-алгебра.
Доказательство. В соответствии с определением sigma\sigma-алгебры требуется показать, во-первых, что для любого B inCB \in \mathcal{C} его дополнение B^(C)inCB^{C} \in \mathcal{C}. Это утверждение следует из тождества
В самом деле, пусть B inCB \in \mathcal{C}. Тогда xi^(-1)(B)\xi^{-1}(B) принадлежит sigma\sigma - алгебре A\mathcal{A}, которая содержит также и его дополнением (xi^(-1)(B))^(C)\left(\xi^{-1}(B)\right)^{C}. Следовательно, B^(C)B^{C} также принадлежит C\mathcal{C}. Во-вторых, требуется показать, что для любого конечное или счетного семейства (B_(j))_(j >= 1)\left(B_{j}\right)_{j \geq 1} подмножеств из C\mathcal{C} их объединение также принадлежит C\mathcal{C}. Это следует из тождества
По определению случайной величины прообраз любого интервала является событием из A\mathcal{A}. Поэтому sigma\sigma-алгебра C\mathcal{C} содержит все интервалы из RR, а также содержит sigma\sigma-алгебру B\mathcal{B}, порожденную интервалами (борелевскую).
называется vv-мерной (или векторной) случайной величиной, определенным на измеримом пространстве ( Omega,A\Omega, \mathcal{A} ), если для любого борелевского множества B inB^(v)B \in \mathcal{B}^{v} его прообраз
xi^(-1)(B)={omega in Omega:xi(omega)in B}\xi^{-1}(B)=\{\omega \in \Omega: \xi(\omega) \in B\}
является событием из A\mathcal{A}.
Ниже перечисляются свойства случайных величин, которые будут использоваться далее. Их доказательства приводятся в курсах по теории вероятностей.
(1.2.2) Пусть (A_(k))_(k >= 1)\left(A_{k}\right)_{k \geq 1} - счетное семейство попарно непересекающихся событий sigma\sigma-алгебры A\mathcal{A}, объединение которых совпадает с Omega\Omega, и пусть (x_(k))_(k >= 1)\left(x_{k}\right)_{k \geq 1} счетное семейство из RR. Тогда отображение xi:Omega rarr R\xi: \Omega \rightarrow R, определяемое равенством
будет случайной величиной на измеримом пространстве ( Omega,A\Omega, \mathcal{A} ).
(1.2.3) Каждое непрерывное отображение вида xi:R^(v)rarr R\xi: R^{v} \rightarrow R является случайной величиной на измеримом пространстве ( R^(v),B^(v)R^{v}, \mathcal{B}^{v} ).
(1.2.4) Множество случайных величин замкнуто относительно основных операций анализа: сложения, вычитания, умножения, деления при отличном от нуля делителя и предельного перехода).
(1.2.5) Пусть vv - некоторое натуральное число и (xi^((k)))_(1 <= k <= v)\left(\xi^{(k)}\right)_{1 \leq k \leq v} - набор отображений вида Omega rarr R\Omega \rightarrow R. Для того, чтобы векторное отображение xi:Omega rarrR^(v)\xi: \Omega \rightarrow R^{v}, определяемое равенством
было векторной случайной величиной необходимо и достаточно, чтобы каждое отображение xi^((k)),1 <= k <= v\xi^{(k)}, 1 \leq k \leq v, было скалярной случайной величиной.
Пусть ( Omega,A,P\Omega, \mathcal{A}, P ) - вероятностное пространство, B^(v)\mathcal{B}^{v} - борелевская sigma\sigma-алгебра на R^(v)R^{v}. Каждая случайная величина xi:Omega rarrR^(v)\xi: \Omega \rightarrow R^{v} определяет на борелевской sigma\sigma-алгебре B^(v)\mathcal{B}^{v} отображение P_(xi):B^(v)rarr RP_{\xi}: \mathcal{B}^{v} \rightarrow R при помощи равенства
P_(xi)(B)=P(xi^(-1)(B))=P(omega in Omega:xi(omega)in B),B inB^(v)P_{\xi}(B)=P\left(\xi^{-1}(B)\right)=P(\omega \in \Omega: \xi(\omega) \in B), B \in \mathcal{B}^{v}
которое является вероятностью на ( R^(v),B^(v)R^{v}, \mathcal{B}^{v} ). Из определения P_(xi)P_{\xi} следует, что P_(xi)(B) >= 0P_{\xi}(B) \geq 0 для любого B inB^(v)B \in \mathcal{B}^{v}. Справедливость аксиомы P_(xi)(R^(v))=1P_{\xi}\left(R^{v}\right)=1 вытекает из очевидного равенства
xi^(-1)(R^(v))={omega in Omega:xi(omega)inR^(v)}=Omega.\xi^{-1}\left(R^{v}\right)=\left\{\omega \in \Omega: \xi(\omega) \in R^{v}\right\}=\Omega .
Вероятность P_(xi)P_{\xi} на борелевской sigma\sigma-алгебре B^(v)B^{v} называется распределением вероятностей или просто распределением случайной величины xi\xi.
Отображение f:R^(v)rarr Rf: R^{v} \rightarrow R называется измеримым по Борелю или борелевским, если для любого борелевского множества B inB^(v)B \in \mathcal{B}^{v} множество
является случайной величиной на ( Omega,A\Omega, \mathcal{A} ).
Доказательство. Для любого борелевского подмножества B inB^(v)B \in \mathcal{B}^{v} получаем
{:[eta^(-1)(B)={omega in Omega:eta(omega)in B}={omega in Omega:f(xi(omega))in B}=],[{omega in Omega:xi(omega)inf^(-1)(B)}=xi^(-1)(f^(-1)(B).:}]:}\begin{gathered}
\eta^{-1}(B)=\{\omega \in \Omega: \eta(\omega) \in B\}=\{\omega \in \Omega: f(\xi(\omega)) \in B\}= \\
\left\{\omega \in \Omega: \xi(\omega) \in f^{-1}(B)\right\}=\xi^{-1}\left(f^{-1}(B) .\right.
\end{gathered}
Так как ff борелевское отображение, то f^(-1)(B)f^{-1}(B) борелевское множество. xi\xi -
случайная величина, поэтому прообраз xi^(-1)(f^(-1)(B))\xi^{-1}\left(f^{-1}(B)\right) борелевского множества f^(-1)(B)f^{-1}(B) является событием из A\mathcal{A}. Что и требовалось доказать.
Определенное выше отображение eta\eta называется обычно суперпозицией отображений ff и xi\xi и обозначается f@xif \circ \xi или f(xi)f(\xi).
Векторная ( vv-мерная) случайная величина xi\xi называется дискретной, если существует не более, чем счетное подмножество Q_(xi)subR^(v)Q_{\xi} \subset R^{v}, такое, что P_(xi)({x}) > 0P_{\xi}(\{x\})>0 для любого x inQ_(xi)x \in Q_{\xi} и что P_(xi)(Q_(xi))=1P_{\xi}\left(Q_{\xi}\right)=1. Подмножество Q_(xi)Q_{\xi} является борелевским и называется множеством значений случайной величины xi\xi. Из равенства
следует, что P_(xi)(Q_(xi)^(C))=0P_{\xi}\left(Q_{\xi}^{C}\right)=0. Поэтому P_(xi)({x})=0P_{\xi}(\{x\})=0 для каждого x inQ_(xi)^(C)x \in Q_{\xi}^{C}. Более того, для любого B inB^(v)B \in \mathcal{B}^{v} справедливо равенство
P_(xi)(B)=sum_(x in B nnQ_(xi))P_(xi)({x}).P_{\xi}(B)=\sum_{x \in B \cap Q_{\xi}} P_{\xi}(\{x\}) .
Пусть xi\xi - mu\mu-мерная, eta-v\eta-v - мерная дискретные случайные величины, принимающие значения в конечных подмножествах Q_(mu)Q_{\mu} и Q_(v)Q_{v} - конечные подмножества в R^(mu)R^{\mu} и R^(v)R^{v} соответственно, а xi-(mu+v)\xi-(\mu+v) - мерная дискретная случайная величина со значениями в множестве Q_(mu)xxQ_(nu)Q_{\mu} \times Q_{\nu} из R^(mu+nu)R^{\mu+\nu}. Тогда
Пусть xi\xi - векторная ( vv-мерная) случайная величина, а P_(xi)P_{\xi} - ее распределение. Неотрицательная измеримая по Борелю функция p_(xi):R^(v)rarr Rp_{\xi}: R^{v} \rightarrow R называется плотностью распределения P_(xi)P_{\xi} случайной величины xi\xi, если для любого борелевского множества B inB^(v)B \in B^{v} имеет место равенство
P_(xi)(B)=int_(B)p_(xi)(x)dxP_{\xi}(B)=\int_{B} p_{\xi}(x) d x
В курсах теории вероятностей доказывается, что для каждого неотрицательного отображения вида p:R^(v)rarr Rp: R^{v} \rightarrow R такого, что
int_(R^(v))p(x)dx=1\int_{R^{v}} p(x) d x=1
существует случайная величина xi\xi, для которой pp является плотностью вероятностей.
Отображение вида
p(x)={[0","x < a],[(x)/(b-a)],[0","b < x],a <= x <= b,:}p(x)=\left\{\begin{array}{l}
0, x<a \\
\frac{x}{b-a} \\
0, b<x
\end{array}, a \leq x \leq b,\right.
является плотностью распределения, которое называется равномерным распределением на интервале [a,b][a, b].
Пусть Y={y_(1),dots,y_(|Y|)}Y=\left\{y_{1}, \ldots, y_{|Y|}\right\} - конечное множество вещественных чисел, в частности Y={0,dots,|Y|-1}Y=\{0, \ldots,|Y|-1\}. Семейство
p(y)=(1)/(|Y|),quad y in Yp(y)=\frac{1}{|Y|}, \quad y \in Y
неотрицательных чисел является распределением дискретной случайной величины, которое называется равномерным распределением на множестве YY.
При решении прикладных задач для описания свойств векторной случайной величины xi_(A)=(xi_(a))_(a in A)\xi_{A}=\left(\xi_{a}\right)_{a \in A} довольно часто вместо |A||A|-мерного распределения P_(Y)^(A)P_{Y}{ }^{A} используют числовые характеристики случайных величин.
Основной числовой характеристикой случайной величины является число, называемое ее средним значением или математическим ожиданием. Пусть P_(xi)=(p_(xi)(x))_(x in Y)P_{\xi}=\left(p_{\xi}(x)\right)_{x \in Y} - распределение дискретной скалярной случайной величины xi\xi со значениями в YY, а p_(eta)p_{\eta} - плотность распределения случайной величины eta\eta. Тогда их средние значения определяются равенствами
E xi=sum_(x_(z)in Y)xp_(xi)(x)" и "E eta=int_(R^(v))xp_(eta)(x)dxE \xi=\sum_{x_{z} \in Y} x p_{\xi}(x) \text { и } E \eta=\int_{R^{v}} x p_{\eta}(x) d x
Ниже перечислены свойства среднего значения, которые будут использоваться далее. Если c-c- константа, то E(c)=c,E(c xi)=cE xiE(c)=c, E(c \xi)=c E \xi,
E(xi+eta)=E xi+E etaE(\xi+\eta)=E \xi+E \eta
Если xi\xi и eta\eta независимы, то
E(xi eta)=E xi E etaE(\xi \eta)=E \xi E \eta
Пусть xi\xi и eta\eta - случайные величины, тогда при любом вещественном xx выполняется неравенство
и следующего из него неравенство 4(E|xi eta|)^(2)-4Exi^(2)Eeta^(2) <= 04(E|\xi \eta|)^{2}-4 E \xi^{2} E \eta^{2} \leq 0. Последнее неравенство, представленное в форме
получило название неравенства Буняковского- Коши-Шварца и буде использоваться далее.
Еще одной числовой характеристикой случайной величины xi\xi со средним значением E xiE \xi является число D xiD \xi, определяемое равенством
D xi=E(xi-E xi)^(2)D \xi=E(\xi-E \xi)^{2}
Оно называется дисперсией xi\xi. Из определения дисперсии немедленно следует, что D xi >= 0,D xi=E(xi)^(2)-(E xi)^(2)D \xi \geq 0, D \xi=E(\xi)^{2}-(E \xi)^{2} и D(c xi)=c^(2)D xiD(c \xi)=c^{2} D \xi. Кроме того, если xi\xi и eta\eta независимы, то
D(xi+eta)=D xi+D etaD(\xi+\eta)=D \xi+D \eta
Квадратный корень из дисперсии D xiD \xi называется среднеквадратическим отклонением или стандартом случайной величины xi\xi и обозначается буквой sigma_(xi)\sigma_{\xi} или просто sigma\sigma, когда это не приводит к неопределенности. Следовательно, sigma_(xi)^(2)=D xi\sigma_{\xi}^{2}=D \xi.
Приведенное ниже неравенство
P(|eta-m_(eta)| >= ksigma_(eta)) <= (1)/(k^(2))P\left(\left|\eta-m_{\eta}\right| \geq k \sigma_{\eta}\right) \leq \frac{1}{k^{2}}
называется неравенством Чебышева. Оно позволяет оценить величину рассеивания (разброса) значений случайной величины относительно ее среднего значения в единицах стандартного отклонения sigma_(eta)\sigma_{\eta}.
Ковариацией случайных величин xi_(z)\xi_{z} и xi_(t)\xi_{t} со средними значениями m_(z)m_{z} и m_(t)m_{t} соответственно называется число cov(xi_(z),xi_(t))\operatorname{cov}\left(\xi_{z}, \xi_{t}\right), определяемое равенством
cov(xi_(z),xi_(z))=sigma_(z)^(2)" и "cov(xi_(z),xi_(t))=cov(xi_(t),xi_(z)).\operatorname{cov}\left(\xi_{z}, \xi_{z}\right)=\sigma_{z}^{2} \text { и } \operatorname{cov}\left(\xi_{z}, \xi_{t}\right)=\operatorname{cov}\left(\xi_{t}, \xi_{z}\right) .
Если xi_(z)\xi_{z} и xi_(t)\xi_{t} независимы, то из свойства E(xi_(z)xi_(t))=Exi_(z)Exi_(t)E\left(\xi_{z} \xi_{t}\right)=E \xi_{z} E \xi_{t} средних значений следует, что cov(xi_(z),xi_(t))=0\operatorname{cov}\left(\xi_{z}, \xi_{t}\right)=0. Обратное утверждение справедливо только для случайных величин с нормальными распределениями.
Нормированным коэффициентом корреляции двух случайных величин xi_(z)\xi_{z} и xi_(t)\xi_{t} называется число R(xi_(z),xi_(t))R\left(\xi_{z}, \xi_{t}\right), определяемое равенством
С помощью неравенства Буняковского-Коши-Шварца, легко убедиться в том, что |R(xi_(z),xi_(t))| <= 1\left|R\left(\xi_{z}, \xi_{t}\right)\right| \leq 1. Если xi_(z)\xi_{z} и xi_(t)\xi_{t} - независимы, то из выше сказанного следует, что R(xi_(z),xi_(t))=0R\left(\xi_{z}, \xi_{t}\right)=0. С другой стороны, пусть xi\xi - случайная величина со средним E xi=mE \xi=m и дисперсией D xi=sigma^(2)D \xi=\sigma^{2}. Пусть c!=0c \neq 0 и dd - вещественные числа и eta=cxi+d\eta=\mathrm{c} \xi+d - случайная величина со средним E eta=cm+dE \eta=c m+d и дисперсией D eta=c^(2)sigma^(2)D \eta=c^{2} \sigma^{2}. Тогда
Таким образом, R(xi,eta)=1R(\xi, \eta)=1 при c > 1c>1 и R(xi,eta)=-1R(\xi, \eta)=-1 при c < 1c<1. Перечисленные свойства коэффициента корреляции позволяют использовать его в качестве меры зависимости между случайными величинами.
Задачи
Определить случайную величину xi\xi с равномерным распределением на интервале [0,1][0,1] (указать Omega,A,P\Omega, A, P и вид отображения xi:Omega rarr R\xi: \Omega \rightarrow R ).
Определить плотность случайной величины с треугольным распределением...
Определить случайную величину xi=(xi_(1),xi_(2))\xi=\left(\xi_{1}, \xi_{2}\right) с равномерным распределением на квадрате [0,1]xx[0,1][0,1] \times[0,1] (указать Omega,A,P\Omega, A, P и вид отображения xi:Omega rarr R)\xi: \Omega \rightarrow R). Показать, что случайные величины xi_(1)\xi_{1} и xi_(2)\xi_{2} независимы.
Определить случайную величину xi=(xi_(1),xi_(2))\xi=\left(\xi_{1}, \xi_{2}\right) с равномерным распределением на круге B(0,1)={(x_(1),x_(2))inR^(2):x_(1)^(2)+x_(2)^(2) <= 1}B(0,1)=\left\{\left(x_{1}, x_{2}\right) \in R^{2}: x_{1}^{2}+x_{2}^{2} \leq 1\right\} (указать Omega,A,P\Omega, A, P и вид отображения xi:Omega rarr R\xi: \Omega \rightarrow R ). Показать, что xi_(1)\xi_{1} и xi_(2)\xi_{2} зависимы.
1.3. Свойства многомерных случайных величин
Пусть nn - натуральное число и (f_(j))_(1 <= j <= n)\left(f_{j}\right)_{1 \leq j \leq n} - семейство отображений вида R^(n)rarr R\boldsymbol{R}^{n} \rightarrow \boldsymbol{R}. Отображение f:R^(n)rarrR^(n)f: \boldsymbol{R}^{n} \rightarrow \boldsymbol{R}^{n}, определяемое равенством
называется гладким, если все отображения f_(j),1 <= j <= nf_{j}, 1 \leq j \leq n, являются непрерывными и имеют непрерывные частные производные. Пусть ff - гладкое отображение. Для любого x inR^(n)x \in \boldsymbol{R}^{n} существует квадратная матрица
порядка nn, элементами которой являются частные производные, вычисленные в xx. Она называется матрицей Якоби, а ее определитель, обозначаемый символом Df(x)D f(x), - якобианом. Таким образом, каждое гладкое отображение ff определяет на множестве R^(n)\boldsymbol{R}^{n} отображение DfD f вида R^(n)rarr R\boldsymbol{R}^{n} \rightarrow \boldsymbol{R}, ставящее каждому xx значение Df(x)D f(x).
Пусть ff - гладкое отображение вида R^(n)rarrR^(n)\boldsymbol{R}^{n} \rightarrow \boldsymbol{R}^{n}. Если в точке x inR^(n)x \in \boldsymbol{R}^{n} якобиан Df(x)!=0D f(x) \neq 0, то в окрестности точки f(x)f(x) существует гладкое обратное отображение f^(-1)f^{-1} и выполняется равенство
Df(x)Df^(-1)(f(x))=1.D f(x) D f^{-1}(f(x))=1 .
Если гладкое отображение f:R^(v)rarrR^(v)f: \boldsymbol{R}^{v} \rightarrow \boldsymbol{R}^{v} является, кроме того, взаимно однозначным, то имеет место формула замены переменных в определенном интеграле
int_(B)g(x)dx=int_(f^(-1)(B))g(f(x))|Df(x)|dx\int_{B} g(x) d x=\int_{f^{-1}(B)} g(f(x))|D f(x)| d x
В качестве примера применим эту формулу для вычисления плотности случайной величины eta=f(xi)\eta=f(\xi).
(1.3.1) Пусть xi=(xi_(j))_(1 <= j <= n)\xi=\left(\xi_{j}\right)_{1 \leq j \leq n} - случайный вектор, p_(xi):R^(n)rarr Rp_{\xi}: \boldsymbol{R}^{n} \rightarrow \boldsymbol{R} - его плотность, а f:R^(n)rarrR^(n)f: \boldsymbol{R}^{n} \rightarrow \boldsymbol{R}^{n} - гладкое взаимно однозначное отображение. Тогда eta=f(xi)\eta= f(\xi) также является nn-мерной случайной величиной, а ее плотность p_(eta)p_{\eta} определяется равенством вида
Теорема доказана. Из нее следует, в частности, что ковариационная матрица C_(xi)C_{\xi} любой векторной случайной величины xi=(xi_(j))_(1 <= j <= n)\xi=\left(\xi_{j}\right)_{1 \leq j \leq n} является неотрицательно определенной. В самом деле, (C_(xi)x,x)=D(x,xi) >= 0\left(C_{\xi} x, x\right)=D(x, \xi) \geq 0 для любого x inR^(n)x \in \boldsymbol{R}^{n}.
Пусть xi=(xi_(j))_(1 <= j <= n)\xi=\left(\xi_{j}\right)_{1 \leq j \leq n} - векторная случайная величина. Говорят, что ее распределение P_(xi)P_{\xi} сосредоточено на множестве QQ из R^(n)\boldsymbol{R}^{n}, если P_(xi)(Q)=1P_{\xi}(Q)=1.
Пусть q in R,a=(a_(j))_(1 <= j <= n)q \in \boldsymbol{R}, a=\left(a_{j}\right)_{1 \leq j \leq n} - вектор из R^(n)\\{0}\boldsymbol{R}^{n} \backslash\{0\}. Подмножество HH из R^(n)\boldsymbol{R}^{n}, определяемое равенством
называется гиперплоскостью.
(1.3.4) Пусть xi=(xi_(j))_(1 <= j <= n)\xi=\left(\xi_{j}\right)_{1 \leq j \leq n} - векторная случайная величина. Для того, чтобы ее распределение P_(xi)P_{\xi} было сосредоточено на некоторой гиперплоскости H subR^(n)H \subset \boldsymbol{R}^{n} необходимо и достаточно, чтобы ковариационная матрица C_(xi)C_{\xi} была вырожденной.
Доказательство необходимости. Пусть HH - гиперплоскость, на которой сосредоточено распределение P_(xi)P_{\xi}. Тогда из P_(xi)(H)=1P_{\xi}(H)=1 следует, что
P(xi^(-1)(H))=P{omega in Omega:xi(omega)in H}=P{omega in Omega:(a,xi(omega))=q}=1.P\left(\xi^{-1}(H)\right)=P\{\omega \in \Omega: \xi(\omega) \in H\}=P\{\omega \in \Omega:(a, \xi(\omega))=q\}=1 .
Следовательно, скалярная случайная величина (a,xi)(a, \xi) принимает с вероятностью равной единице значение qq. Это означает, что ее дисперсия D(a,xi)=0D(a, \xi)=0. Из (1.3.2) следует, что (C_(xi)a,a)=0\left(C_{\xi} a, a\right)=0 при a inR^(n)\\{0}a \in \boldsymbol{R}^{n} \backslash\{0\}. Если квадратичная форма обращается в ноль при ненулевом векторе a inR^(n)\\{0}a \in \boldsymbol{R}^{n} \backslash\{0\}, то ее матрица C_(xi)C_{\xi} называется вырожденной.
Достаточность. Пусть ковариационная матрица C_(xi)C_{\xi} - вырождена. Тогда существует такое a inR^(n)\\{0}a \in R^{n} \backslash\{0\}, что (C_(xi)a,a)=0\left(C_{\xi} a, a\right)=0. Из (2.3.2) следует, что дисперсия D(a,xi)=0D(a, \xi)=0. Это означает, что существует q in Rq \in \boldsymbol{R} такое, что вероятность равенства (a,xi)=q(a, \xi)=q равна единице. То есть
P{omega in Omega:(a,xi(omega))=q}=P({omega in Omega:xi(omega)in H}=P(xi^(-1)(H))=P_(xi)(H)=1.:}P\{\omega \in \Omega:(a, \xi(\omega))=q\}=P\left(\{\omega \in \Omega: \xi(\omega) \in H\}=P\left(\xi^{-1}(H)\right)=P_{\xi}(H)=1 .\right.
Теорема доказана.
(1.3.5) Пусть xi=(xi_(j))_(1 <= j <= n)-n\xi=\left(\xi_{j}\right)_{1 \leq j \leq n}-n-мерная случайная величина, C_(xi)-C_{\xi}- ее матрица ковариаций, a=(a_(j))_(1 <= j <= m)a=\left(a_{j}\right)_{1 \leq j \leq m} - вектор из R^(m)\boldsymbol{R}^{m} и A=(a_(ij))_(1 <= i <= m,1 <= j <= n)A=\left(a_{i j}\right)_{1 \leq i \leq m, 1 \leq j \leq n} матрица размерности m xx nm \times n. Тогда eta=A xi+a\eta=A \xi+a является mm-мерной случайной величиной с матрицей ковариации
C_(eta)=AC_(xi)A^(t).C_{\eta}=A C_{\xi} A^{t} .
Доказательство. Для любого i,1 <= i <= mi, 1 \leq i \leq m, отображение f_(i):R^(n)rarr Rf_{i}: \boldsymbol{R}^{n} \rightarrow \boldsymbol{R}, определяемое равенством
является непрерывной функцией. Поэтому eta_(i)=f_(i)(xi)\eta_{i}=f_{i}(\xi) - скалярная случайная величина, а eta=A xi+a\eta=A \xi+a - векторная. Используя (2.3.2), для каждого x inR^(n)x \in \boldsymbol{R}^{n} получаем
D(x,eta)=D(x,A xi+a)=0+D(x,A xi)=D(x,A xi).D(x, \eta)=D(x, A \xi+a)=0+D(x, A \xi)=D(x, A \xi) .
Из непосредственно проверяемого тождества (x,Ay)=(A^(t)x,y)(x, A y)=\left(A^{t} x, y\right), где xx и yy векторы из R^(n)\boldsymbol{R}^{n}, а AA - квадратная матрица порядка nn, следует, что
С другой стороны, на основании (2.3.2) имеем равенство D(x,eta)=(C_(eta)x,x)D(x, \eta)=\left(C_{\eta} x, x\right), из которого следует утверждение теоремы.
Задачи
Пусть xx и yy векторы из R^(n)\boldsymbol{R}^{n}, а AA - квадратная матрица порядка nn. Доказать тождество (x,Ay)=(A^(t)x,y)(x, A y)=\left(A^{t} x, y\right).
1.4. Многомерное нормальное распределение
Говорят, что одномерная случайная величина xi\xi имеет стандартное одномерное нормальное распределение, если его плотность p_(xi)p_{\xi} определяется равенCTBOM
Непосредственным вычислением можно убедиться в том, что ее среднее значение E xi=0E \xi=0, а дисперсия D xi=1D \xi=1. Если eta=sigma xi+a\eta=\sigma \xi+a, то E eta=aE \eta=a и D eta=sigma^(2)D \eta=\sigma^{2}. Распределение случайной величины eta\eta называется одномерным нормальным распределением с параметрами N(a,sigma)N(a, \sigma). Из (1.3.2) следует, что плотность ее распределения имеет вид
Распределение nn-мерного случайного вектора xi=(xi_(j))_(1 <= j <= n)\boldsymbol{\xi}=\left(\xi_{j}\right)_{1 \leq j \leq n} с независимыми компонентами принято называть nn-мерным стандартным нормальным распределением, если каждая одномерная компонента имеет стандартное нормальное распределение с параметрами N(0,1)N(0,1). В этом случае
а матрица ковариаций C_(xi)=EC_{\xi}=E. В самом деле, если i!=ji \neq j, то cov(xi_(i),xi_(j))=Exi_(i)Exi_(j)=0\operatorname{cov}\left(\xi_{i}, \xi_{j}\right)= E \xi_{i} E \xi_{j}=0, в остальных случаях cov(xi_(i),xi_(i))=E(xi_(i))^(2)=1\operatorname{cov}\left(\xi_{i}, \xi_{i}\right)=E\left(\xi_{i}\right)^{2}=1.
Пусть AA - квадратная матрица порядка n,xi=(xi_(j))_(1 <= j <= n)n, \boldsymbol{\xi}=\left(\xi_{j}\right)_{1 \leq j \leq n} - случайный вектор со стандартным нормальным распределением и a inR^(n)\boldsymbol{a} \in \boldsymbol{R}^{n}. Распределение случайного вектора eta=(eta_(j))_(1 <= j <= n)\boldsymbol{\eta}=\left(\eta_{j}\right)_{1 \leq j \leq n}, определяемого равенством eta=A xi+a\boldsymbol{\eta}=A \boldsymbol{\xi}+\boldsymbol{a}, называется nn-мерным нормальным распределением. Так как
то Eeta_(j)=a_(j)E \eta_{j}=a_{j}. Так как C_(xi)=EC_{\xi}=E, то из (1.3.5) следует, что C_(eta)=AC_(xi)A^(t)=AA^(t)C_{\eta}=A C_{\xi} A^{t}=A A^{t}.
(1.4.1) Если xi=(xi_(j))_(1 <= j <= n)\boldsymbol{\xi}=\left(\xi_{j}\right)_{1 \leq j \leq n} - случайный вектор со стандартным nn-мерным нормальным распределением, а eta=A xi+a\boldsymbol{\eta}=A \boldsymbol{\xi}+\boldsymbol{a}, то плотность p_(eta)np_{\boldsymbol{\eta}} n-мерного нормального распределения случайного вектора eta\boldsymbol{\eta} имеет вид
Доказательство. Покажем, что отображение f(x)=Ax+af(x)=A x+a вида R^(n)rarrR^(n)\boldsymbol{R}^{n} \rightarrow \boldsymbol{R}^{n} является гладким взаимно однозначным и воспользуемся для вычисления p_(eta)p_{\eta} теоремой (1.3.1). Из нее следует, что
то ff является гладким. Поэтому в каждой точке x inR^(n)x \in R^{n} Якобиан отображения f=(f_(j))_(1 <= j <= n)f=\left(f_{j}\right)_{1 \leq j \leq n} равен Df(x)=det(A)D f(x)=\operatorname{det}(A). При det(A)!=0\operatorname{det}(A) \neq 0 прообраз любого x inR^(n)x \in \boldsymbol{R}^{n}
f^(-1)(x)={t inR^(n):At+a=x}={t inR^(n):t=A^(-1)(x-a)}=A^(-1)(x-a)f^{-1}(x)=\left\{t \in \boldsymbol{R}^{n}: A t+a=x\right\}=\left\{t \in \boldsymbol{R}^{n}: t=A^{-1}(x-a)\right\}=A^{-1}(x-a)
является вектор A^(-1)(x-a)A^{-1}(x-a), то отображение ff является взаимно однозначным. Из Df(x)=det(A)D f(x)=\operatorname{det}(A) и Df(x)Df^(-1)(f(x))=1D f(x) D f^{-1}(f(x))=1 следует, что
С другой стороны, det(C_(eta))=det(A)(detA^(t))=(det(A))^(2)\operatorname{det}\left(C_{\eta}\right)=\operatorname{det}(A)\left(\operatorname{det} A^{t}\right)=(\operatorname{det}(A))^{2}. Поэтому det(A)=sqrt(det(C_(eta)))\operatorname{det}(A)=\sqrt{\operatorname{det}\left(C_{\eta}\right)}. Применяя (2.3.1), получаем
После применения известного тождества {:(x,Ay)=(A^(t)x,y))\left.(x, A y)=\left(A^{t} x, y\right)\right), где xx и yy векторы из R^(n)\boldsymbol{R}^{n}, а AA - квадратная матрица порядка nn, к скалярному произведению из правой части, имеем
Транспонируя равенство AA^(-1)=EA A^{-1}=E, имеем (A^(-1))^(t)A^(t)=E\left(A^{-1}\right)^{t} A^{t}=E. После умножения обеих его частей справа на (A^(t))^(-1)\left(A^{t}\right)^{-1} получаем равенство (A^(-1))^(t)=(A^(t))^(-1)\left(A^{-1}\right)^{t}=\left(A^{t}\right)^{-1}. Поэтому
чем и завершается доказательство.
Таким образом, nn-мерное нормальное распределение случайного вектора eta\eta определяется его вектором aa средних значений и ковариационной матрицей C_(eta)C_{\eta} и кратко обозначается N(a,C_(eta))N\left(a, C_{\eta}\right). Если det(C_(eta))=0\operatorname{det}\left(C_{\eta}\right)=0, то из (2.3.3) следует, что нормальное распределение сосредоточено на гиперплоскости. В этом случае плотность p_(eta)p_{\eta} распределения в R^(n)\boldsymbol{R}^{n} не существует.
Задачи
Пусть xi\xi - случайный вектор с nn-мерным нормальным распределением N(a,C_(xi)),BN\left(a, C_{\xi}\right), B - матрица размерности m xx nm \times n и b inR^(m)b \in R^{m}. Показать, что случайный вектор eta=B xi+b\eta=B \xi+b имеет нормальное mm-мерное распределение с параметрами N(Ba+b,C_(xi)BC_(xi)^(t))N\left(B a+b, C_{\xi} B C_{\xi}^{t}\right).
1.5 Бесконечные семейства случайных величин и теорема Колмогорова
Пусть ( Omega,A,P\Omega, \mathcal{A}, P ) - вероятностное пространство, Z^(2)Z^{2} - двумерная целочисленная решетка, C subZ^(2)C \subset Z^{2} и xi_(C)=(xi_(c))_(c in C)\xi_{C}=\left(\xi_{c}\right)_{c \in C} - векторная ( |C||C|-мерная) случайная величина. Ее значениями являются, очевидно, наборы x_(C)x_{C} из множества
Y^(C)={x_(C)=(x_(c))_(c in C):x_(c)in Y,quad c in C}.Y^{C}=\left\{x_{C}=\left(x_{c}\right)_{c \in C}: x_{c} \in Y, \quad c \in C\right\} .
Для каждого x_(C)=(x_(c))_(c in C)x_{C}=\left(x_{c}\right)_{c \in C} из Y^(C)Y^{C} его вероятность p_(Y)c(x_(C))p_{Y} c\left(x_{C}\right) определяется равенством
p_(Y)c(x_(C))=P(omega in Omega:xi_(C)(omega)=x_(C)).p_{Y} c\left(x_{C}\right)=P\left(\omega \in \Omega: \xi_{C}(\omega)=x_{C}\right) .
Из определения дискретной случайной величины следует, что
Распределение вероятностей P_(Y)C=(p_(Y)c(x_(C)))_(x_(C)in Y)P_{Y} C=\left(p_{Y} c\left(x_{C}\right)\right)_{x_{C} \in Y} с векторной случайной величины xi_(C)\xi_{C} принято называть конечномерным распределением.
Пусть AA - подмножество CC, а B=C\\AB=C \backslash A. Тогда xi_(A)=(xi_(a))_(a in A)\xi_{A}=\left(\xi_{a}\right)_{a \in A} и xi_(B)=(xi_(b))_(b in B)\xi_{B}= \left(\xi_{b}\right)_{b \in B} - также векторные случайные величины со значениями в Y^(A)Y^{A} и Y^(B)Y^{B} и распределениями P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} и P_(Y^(B))=(p_(Y^(B))(x_(B)))_(x_(B)inY^(B))P_{Y^{B}}=\left(p_{Y^{B}}\left(x_{B}\right)\right)_{x_{B} \in Y^{B}}. Так как C=A+B,x_(C)=(x_(A),x_(B))C= A+B, x_{C}=\left(x_{A}, x_{B}\right), то имеет место равенство
Пусть каждому конечному подмножеству CC из Z^(2)Z^{2} поставлено в соответствие распределение вероятностей P_(Y)c=(p_(Y)c(x_(C)))_(x_(C)in Y)P_{Y} c=\left(p_{Y} c\left(x_{C}\right)\right)_{x_{C} \in Y}. Конечномерные распределения, образующие семейство называются согласованными, если для них выполняется указанное выше равенство.
Семейство (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} дискретных случайных величин, определенных на (Omega,A)(\Omega, \mathcal{A}), со значениями в конечном множестве YY называется случайным полем на Z^(2)Z^{2}. В 1933 году вышла книга А.Н. Колмогорова с названием «Основные понятия теории вероятностей». В ней доказана теорема, в которой утверждается, что перечисленные выше условия являются не только необходимыми, но и достаточными для существования случайного поля. Применительно к рассматриваемому случаю ее формулировка выглядит следующим образом.
(1.5.1) Пусть YY - конечное подмножество из RR, и пусть каждому конечному подмножеству A subZ^(2)A \subset Z^{2} поставлено в соответствие конечномерное распределение вероятностей P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} на Y^(A)Y^{A}. Если эти распределения
являются согласованными, то существует случайное поле (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} такое, что для любого x_(A)=(x_(a))_(a in A)x_{A}=\left(x_{a}\right)_{a \in A} выполняется равенство
P(omega in Omega:xi_(A)(omega)=x_(A))=p_(Y^(A))(x_(A)).P\left(\omega \in \Omega: \xi_{A}(\omega)=x_{A}\right)=p_{Y^{A}}\left(x_{A}\right) .
Доказательство теоремы Колмогорова можно найти в работах [XXX]. В следующем подразделе предлагается пример ее применения.
При любом фиксированном omega in Omega\omega \in \Omega каждая случайная величина xi_(z),z inZ^(2)\xi_{z}, z \in Z^{2}, принимает некоторое значение x_(z)=xi_(z)(omega)x_{z}=\xi_{z}(\omega) из YY. Таким образом, каждое omega in Omega\omega \in \Omega определяет семейство x=(x_(z))_(z inZ^(2))x=\left(x_{z}\right)_{z \in Z^{2}}. Оно называется реализацией или выборочной поверхностью случайного поля.
1.6 Примеры случайных полей
Очевидно, что распределение P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} на Y^(A)Y^{A} состоит из |Y|^(|A|)|Y|^{|A|} вероятностей. При решении прикладных задач априорные сведения о свойствах сцены, необходимые для определения вероятностей, образующих распределение P_(Y)^(A)P_{Y}{ }^{A}, часто отсутствуют. В этих условиях приходится идти на различные ограничения. Одним из таких ограничений может быть предположение о независимости случайных величин, образующих поле (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}}. Оно позволяет представить вероятность p_(Y^(A))(x_(A))p_{Y^{A}}\left(x_{A}\right) в виде произведения из |A||A| вероятностей p_(Y){a}(x_(a)),a in Ap_{Y}\{a\}\left(x_{a}\right), a \in A :
p_(Y^(A))(x_(A))=prod_(a in A)p_(Y^({a}))(x_(a)).p_{Y^{A}}\left(x_{A}\right)=\prod_{a \in A} p_{Y^{\{a\}}}\left(x_{a}\right) .
Очевидно, что для задания распределения P_(Y^({a}))=(p_(Y^({a}))(y))_(y in Y)P_{Y^{\{a\}}}=\left(p_{Y^{\{a\}}}(y)\right)_{y \in Y} случайной величины xi_(a),a in A\xi_{a}, a \in A, требуется всего |Y||Y| вероятностей. Поэтому для задания распределения P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} на множестве Y^(A)Y^{A} требуется |A||Y||A||Y| вероятностей вида p_(Y^({a}))(x_(a))p_{Y^{\{a\}}}\left(x_{a}\right) вместо |Y|^(|A|)|Y|^{|A|} вероятностей p_(Y^(A))(x_(A))p_{Y^{A}}\left(x_{A}\right).
Осталось только убедиться в том, что определенный выше набор неотрицательных чисел p_(Y^(A))(x_(A))p_{Y^{A}}\left(x_{A}\right) на самом деле является конечномерным распределением на Y^(A)Y^{A} и для семейства всех таких распределений выполняются условия согласованности. Покажем вначале, что
{:[sum_(x_(A)inY^(A))(prod_(a in A)p_(Y^({a}))(x_(a)))=sum_(x_(b)in Y,b in A\\{a})sum_(x_(a)in Y)(p_(Y^({a}))(x_(a))prod_(b in A\\{a})p_(Y^({b}))(x_(b)))=],[sum_(x_(b)in Y,b in A\\{a})prod_(b in A\\{a})p_(Y^({b}))(x_(b))sum_(x_(a)in Y)p_(Y^({a}))(x_(a))=sum_(x_(b)in Y,b in A\\{a})prod_(b in A\\{a})p_(Y^({b}))(x_(b))]:}\begin{gathered}
\sum_{x_{A} \in Y^{A}}\left(\prod_{a \in A} p_{Y^{\{a\}}}\left(x_{a}\right)\right)=\sum_{x_{b} \in Y, b \in A \backslash\{a\}} \sum_{x_{a} \in Y}\left(p_{Y^{\{a\}}}\left(x_{a}\right) \prod_{b \in A \backslash\{a\}} p_{Y^{\{b\}}}\left(x_{b}\right)\right)= \\
\sum_{x_{b} \in Y, b \in A \backslash\{a\}} \prod_{b \in A \backslash\{a\}} p_{Y^{\{b\}}}\left(x_{b}\right) \sum_{x_{a} \in Y} p_{Y^{\{a\}}}\left(x_{a}\right)=\sum_{x_{b} \in Y, b \in A \backslash\{a\}} \prod_{b \in A \backslash\{a\}} p_{Y^{\{b\}}}\left(x_{b}\right)
\end{gathered}
Введя обозначение B=A\\{a}B=A \backslash\{a\}, приходим к сумме
sum_(x_(b)in Y,b in A\\{a})prod_(b in A\\{a})p_(Y^({b}))(x_(b))=sum_(x_(B)inY^(B))(prod_(b in B)p_(Y^({b}))(x_(b))),\sum_{x_{b} \in Y, b \in A \backslash\{a\}} \prod_{b \in A \backslash\{a\}} p_{Y^{\{b\}}}\left(x_{b}\right)=\sum_{x_{B} \in Y^{B}}\left(\prod_{b \in B} p_{Y^{\{b\}}}\left(x_{b}\right)\right),
в которой на одно слагаемое меньше, чем в первоначальной сумме. Результатом последовательного выполнения указанных операций ( |A|-1|A|-1 ) раз является равенство
означающее, что семейство P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} действительно является распределением на Y^(A)Y^{A}.
Осталось показать, что распределения P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}}, сопоставленные всем конечным подмножествам из Z^(2)Z^{2}, являются согласованными. Пусть AA и BB - непересекающиеся подмножества Z^(2)Z^{2}. В этом случае
{:[sum_(x_(B)inY^(B))p_(Y^(A+B))(x_(A+B))=sum_(x_(B)inY^(B))(prod_(c in A+B)p_(Y^({c}))(x_(c)))=],[sum_(x_(B)inY^(B))(prod_(a in A)p_(Y^({a}))(x_(a))prod_(b in B)p_(Y^({b}))(x_(b)))=prod_(a in A)p_(Y^({a}))(x_(a))sum_(x_(B)inY^(B))(prod_(b in B)p_(Y^({b}))(x_(b)))=],[=p_(Y^(A))(x_(A))sum_(x_(B)inY^(B))p_(Y^(B))(x_(B))=p_(Y^(A))(x_(A))]:}\begin{gathered}
\sum_{x_{B} \in Y^{B}} p_{Y^{A+B}}\left(x_{A+B}\right)=\sum_{x_{B} \in Y^{B}}\left(\prod_{c \in A+B} p_{Y^{\{c\}}}\left(x_{c}\right)\right)= \\
\sum_{x_{B} \in Y^{B}}\left(\prod_{a \in A} p_{Y^{\{a\}}}\left(x_{a}\right) \prod_{b \in B} p_{Y^{\{b\}}}\left(x_{b}\right)\right)=\prod_{a \in A} p_{Y^{\{a\}}}\left(x_{a}\right) \sum_{x_{B} \in Y^{B}}\left(\prod_{b \in B} p_{Y^{\{b\}}}\left(x_{b}\right)\right)= \\
=p_{Y^{A}}\left(x_{A}\right) \sum_{x_{B} \in Y^{B}} p_{Y^{B}}\left(x_{B}\right)=p_{Y^{A}}\left(x_{A}\right)
\end{gathered}
Таким образом, построенное семейство конечномерных распределений является согласованным. По теореме Колмогорова существует случайное поле, для которого распределения, образующие семейство, будут конечномерными распределениями.
Следующим упрощением, вызванным теми же причинами, является предположение о том, что все случайные величины, образующие векторную случайную величину xi_(A)\xi_{A}, имеют одно и тоже распределение: p_(Y){a}(y)=p_(A)(y)p_{Y}\{a\}(y)=p_{A}(y) для любых a in Aa \in A и любых y in Yy \in Y. В этом случае для любого x_(A)=(x_(a))_(a in A)inY^(A)x_{A}=\left(x_{a}\right)_{a \in A} \in Y^{A} вероятность p_(Y^(A))(x_(A))p_{Y^{A}}\left(x_{A}\right) принимает вид
p_(Y^(A))(x_(A))=prod_(a in A)p_(Y^({a}))(x_(a))=prod_(a in A)p_(A)(x_(a)).p_{Y^{A}}\left(x_{A}\right)=\prod_{a \in A} p_{Y^{\{a\}}}\left(x_{a}\right)=\prod_{a \in A} p_{A}\left(x_{a}\right) .
Таким образом, последнее предположение позволяет обойтись для задания конечномерного распределения P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} только |Y||Y| вероятностями распределения P_(A)=(p_(A)(y))_(y in Y)P_{A}=\left(p_{A}(y)\right)_{y \in Y}. Пример изображения случайного поля с такими свойствами приводится в конце подраздела.
Из определения построенного случайного поля следует, что образующие его случайные величины являются независимыми в совокупности и имеют одно и тоже распределение. Для случайных полей, используемых при решении прикладных задач, такое свойство является скорее исключением, а не правилом. Ниже предлагается способ построения случайного поля, между случайными величинами которого существует статистическая зависимость. Для его построения воспользуемся только что полученным результатом.
Пусть (zeta_(z))_(z inZ^(2))\left(\zeta_{z}\right)_{z \in Z^{2}} - случайное поле из независимых скалярных случай-
ных величин, имеющих одно и то же распределение со средним значением равным нулю и дисперсией sigma^(2)\sigma^{2}. Тогда
cov(zeta_(z),zeta_(t))=Ezeta_(z)zeta_(t)={[sigma^(2)","z=t],[0","z!=t]:}\operatorname{cov}\left(\zeta_{z}, \zeta_{t}\right)=E \zeta_{z} \zeta_{t}=\left\{\begin{array}{c}
\sigma^{2}, z=t \\
0, z \neq t
\end{array}\right.
Квадратной окрестностью точки z inZ^(2)z \in Z^{2} с радиусом hat(r)\hat{r} будем называть подмножество вида
состоящая из |B(z, hat(r))|=(2 hat(r)+1)^(2)|B(z, \hat{r})|=(2 \hat{r}+1)^{2} точек. Для каждого z inZ^(2)z \in Z^{2} определим случайную величину xi_(z)\xi_{z} равенством
По аналогии со случайными последовательностями (см., например [63, c. 83]) назовем семейство (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} случайным полем, полученным из случайного поля (zeta_(z))_(z inZ^(2))\left(\zeta_{z}\right)_{z \in Z^{2}} скользящим суммированием по окрестности B(z, hat(r))B(z, \hat{r}).
Легко подсчитать, что для каждого z inZ^(2)z \in Z^{2} среднее значение Exi_(z)=0E \xi_{z}=0, дисперсия D(xi_(z))=sigma^(2)//(2 hat(r)+1)^(2)D\left(\xi_{z}\right)=\sigma^{2} /(2 \hat{r}+1)^{2}, а
{:[Exi_(z)xi_(z+t)=E((1)/(|B(z,( hat(r)))|)sum_(s in B(z, hat(r)))zeta_(s)(1)/(|B(z,( hat(r)))|)sum_(s in B(z+t, hat(r)))zeta_(s))=],[(1)/((2( hat(r))+1)^(4))(sum_(s in B(z, hat(r)))sum_(u in B(z+t, hat(r)))Ezeta_(s)zeta_(u))]:}\begin{aligned}
E \xi_{z} \xi_{z+t}= & E\left(\frac{1}{|B(z, \hat{r})|} \sum_{s \in B(z, \hat{r})} \zeta_{s} \frac{1}{|B(z, \hat{r})|} \sum_{s \in B(z+t, \hat{r})} \zeta_{s}\right)= \\
& \frac{1}{(2 \hat{r}+1)^{4}}\left(\sum_{s \in B(z, \hat{r})} \sum_{u \in B(z+t, \hat{r})} E \zeta_{s} \zeta_{u}\right)
\end{aligned}
Если окрестности B(z, hat(r))B(z, \hat{r}) и B(z+t, hat(r))B(z+t, \hat{r}) не пересекаются (|t| > 2 hat(r)sqrt2)(|t|>2 \hat{r} \sqrt{2}), то s!=us \neq u. В этом случае все слагаемые в двойной сумме равны нулю. Поэтому и Exi_(z)xi_(z+t)=0E \xi_{z} \xi_{z+t}=0. В противном случае, если окрестности B(z, hat(r))B(z, \hat{r}) и B(z+t, hat(r))B(z+t, \hat{r}) пересекаются (это может произойти, когда 0 <= |t| <= widehat(2)rsqrt20 \leq|t| \leq \widehat{2} r \sqrt{2} ), то среди всех (2 hat(r)+1)^(4)(2 \hat{r}+1)^{4} слагаемых двойной суммы присутствуют |B(z, hat(r))nn B(z+t, hat(r))||B(z, \hat{r}) \cap B(z+t, \hat{r})| слагаемых вида Ezeta_(z)zeta_(z)=sigma^(2)E \zeta_{z} \zeta_{z}=\sigma^{2}. В этом случае
Осталось показать, что ковариация не завит от сдвига, то есть Exi_(z)xi_(z+t)=Exi_(z+a)xi_(z+t+a)E \xi_{z} \xi_{z+t}=E \xi_{z+a} \xi_{z+t+a} при любом a inZ^(2)a \in Z^{2}. Так как
Пусть u in B(z+a, hat(r))nn B(z+t+a, hat(r))u \in B(z+a, \hat{r}) \cap B(z+t+a, \hat{r}), тогда должны выполняться при j=1,2j=1,2 неравенства |(z_(j)+t_(j)+a_(j))-u_(j)| <= hat(r)\left|\left(z_{j}+t_{j}+a_{j}\right)-u_{j}\right| \leq \hat{r} и |(z_(j)+a_(j))-u_(j)| <= hat(r)\left|\left(z_{j}+a_{j}\right)-u_{j}\right| \leq \hat{r}. Эти же неравенства после перегруппировки слагаемых |(z_(j)+t_(j))-(u_(j)+a_(j))| <= hat(r)\left|\left(z_{j}+t_{j}\right)-\left(u_{j}+a_{j}\right)\right| \leq \hat{r} и |(z_(j))-(u_(j)+a_(j))| <= hat(r)\left|\left(z_{j}\right)-\left(u_{j}+a_{j}\right)\right| \leq \hat{r} означают, что (u+a)in B(z, hat(r))nn B(z+t, hat(r))(u+a) \in B(z, \hat{r}) \cap B(z+t, \hat{r}). Тем самым доказано включение
называется ковариационной функцией случайного поля (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}}. Из доказанного выше следует, что для случайных полей, получаемых скользящим суммированием, выполняется равенство
Оно означает, что значение r(z,t)r(z, t) ковариационной функции зависит только от разности (z-t)(z-t). Случайные поля с такими ковариационными функциями и средними значениями, не зависящими от z inZ^(2)z \in Z^{2}, называются однородными в широком смысле. Их ковариационные функции являются отображениями вида r:Z^(2)rarr Rr: Z^{2} \rightarrow R. Поэтому значение r(t)r(t) ковариационной функции случайного поля, полученного скользящим суммирование, определя-
В таблицах 2.1 и 2.2 указаны ненулевые значения ковариационных
функций случайных полей, полученных скользящим суммированием с радиусами hat(r)=2\hat{r}=2 и hat(r)=1\hat{r}=1 соответственно. Нетрудно убедиться в том, что при hat(r)=1\hat{r}=1 ковариационная функция зависит только от расстояния |t-z||t-z| между случайными величинами xi_(t)\xi_{t} и xi_(z)\xi_{z}. Случайны поля с такими функциями называются однородными и изотропными.
Таблица 2.1 - Ковариационная функция ( hat(r)=2\hat{r}=2 )
Ниже приведены квадратные фрагменты со стороной 256 пикселей изображений трех случайных полей, полученные с помощью компьютера. Изображение с рисунка 1.5.1 соответствует случайному полю из независимых в совокупности случайных величин, имеющим нормальное распределение со средним значением m=128m=128 и СКО sigma=30\sigma=30. В таблице 2.3 приведены оценки значений нормированной ковариационной функции, вычисленные по этому изображению. Они хорошо согласуются с теоретическими значениями.
Таблица 2.3 - Оценка ковариационной функции ( hat(r)=0\hat{r}=0 )
На рисунках 1.5.2 и 1.5.3 приведены изображения случайных полей, полученных скользящим суммированием по окрестностям B(z, hat(r))B(z, \hat{r}) с радиусами hat(r)=1\hat{r}=1 и hat(r)=2\hat{r}=2 соответственно из случайного поля из независимых в совокупности случайных величин. Оценки средних значений, вычисленные по изображениям этих полей, совпали со средним значением исходного случайного поля. Оценки СКО равны 10 и 6 уровням, что совпало с теоретическими значениями. В таблицах 2.4 и 2.5 приведены оценки значений нормированных ковариационных функций, вычисленные по соответствующим изображениям...
Рисунок 1.5.1 - Изображение случайного поля с попарно независимыми случайными величинами
Рисунок 1.5.2 - Изображение случайного поля, полученного скользящим
Ковариационная функция. Характеристическое свойство ковариационной функции. Определение однородного случайного поля и свойства его ковариационной функции.
Если задано случайное поле (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}}, то каждой паре zz и tt из Z^(2)Z^{2} можно поставить в соответствие ковариацию cov(xi_(z),xi_(t))=E(xi_(z)-Exi_(z))(xi_(t)-Exi_(t))\operatorname{cov}\left(\xi_{z}, \xi_{t}\right)=E\left(\xi_{z}-E \xi_{z}\right)\left(\xi_{t}-E \xi_{t}\right) случайных величин xi_(z)\xi_{z} и xi_(t)\xi_{t}. Отображение r:Z^(2)rarr Rr: Z^{2} \rightarrow R, определяемое равенством r(z,t)=cov(xi_(z),xi_(t))r(z, t)=\operatorname{cov}\left(\xi_{z}, \xi_{t}\right), называется ковариационной функцией случайного поля.
(1.7.1) Пусть nn - натуральное число, c_(j),1 <= j <= nc_{j}, 1 \leq j \leq n, - произвольные вещественные числа, среди которых не все нули, тогда имеет место неравенство
при любых вещественных c_(j),1 <= j <= nc_{j}, 1 \leq j \leq n, и любых z_(j),t_(i)z_{j}, t_{i} из Z^(2)Z^{2}, называются неотрицательно определенными. Из доказанной теоремы следует, что каждая ковариационная функция является таковой. Следующая теорема утверждает, что верно и обратное утверждение.
(1.7.2) Если ff - неотрицательно определенная на Z^(2)Z^{2} функция, то существует случайное поле (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} со средним значением m_(z)=0,z inZ^(2)m_{z}=0, z \in Z^{2}, для которого ff является ковариационной функцией
Exi_(z)xi_(t)=f(xi_(z),xi_(t)),z inZ^(2),t inZ^(2).E \xi_{z} \xi_{t}=f\left(\xi_{z}, \xi_{t}\right), z \in Z^{2}, t \in Z^{2} .
С доказательством теоремы можно ознакомиться по работам [XX]. А здесь намечены его основные этапы. Ранее в 1.4 показано, что нормальное распределение nn-мерной случайной величины xi=(xi_(j))_(1 <= j <= n)\xi=\left(\xi_{j}\right)_{1 \leq j \leq n} однозначно определяется вектором средних значений m=(m_(j))_(1 <= j <= n),m_(j)=Exi_(j)m=\left(m_{j}\right)_{1 \leq j \leq n}, m_{j}=E \xi_{j} и ковариационной матрицей C=(c_(ij))_(1 <= i,j <= n),c_(ij)=cov(xi_(i),xi_(j))C=\left(c_{i j}\right)_{1 \leq i, j \leq n}, c_{i j}=\operatorname{cov}\left(\xi_{i}, \xi_{j}\right), которая является неотрицательно определенной. Пусть rr - неотрицательно определенная функция на Z^(2)Z^{2}. Каждому конечному подмножеству A subZ^(2)A \subset Z^{2} можно сопоставить, используя rr, неотрицательно определенную ковариационную матрицу r(z,t)=cov(xi_(z),xi_(t))r(z, t)=\operatorname{cov}\left(\xi_{z}, \xi_{t}\right), z,t in Az, t \in A. Она задает |A||\mathrm{A}| - мерное нормальное распределение векторной случайной величины (xi_(a))_(a in A)\left(\xi_{a}\right)_{a \in A}. Доказывается, что семейство таких распределений является согласованным. В соответствии с теоремой Колмогорова оно задает на Z^(2)Z^{2} случайное поле, ковариационной функцией которого является rr.
Случайная величина считается заданной, если известно ее распределение вероятностей. Однако важная информация о случайной величине содержится в ее числовых характеристиках, главными из которых являются среднее значение и дисперсия. Если для решения поставленной задачи достаточно только этой информации, то можно использовать любую случайную величину с заданными средним значением и дисперсией. При этом следует помнить, что для задания случайной величины этих сведений недостаточно. Оказывается, что похожим образом обстоят дела и в случае случайных полей. При решении широкого класса прикладных задач оказывается достаточно знать только среднее значение (m_(z))_(z inZ^(2))\left(m_{z}\right)_{z \in Z^{2}} и ковариационную функцию rr случайного поля. Поэтому для его задания вместо семейства согласованных конечномерных распределений, можно использовать неотрицательно определенную функцию с нужными свойствами. Теорема (1.7.2) утверждает, что всегда существует случайное поле, для которого она является ковариационной функцией.
Довольно часто предполагается, что свойства случайного поля, описываемые средним значением и ковариационной функцией, должны оставаться неизменными для различных z inZ^(2)z \in Z^{2}. Формально это приводит к требованиям о том, что среднее значение m_(z)m_{z} поля должно быть константой: m_(z)=m,z inZ^(2)m_{z}=m, z \in Z^{2}, а значение ковариационной функции не должно изменяться при сдвиге на произвольный вектор a inZ^(2)a \in Z^{2}
Случайные поля, удовлетворяющие этому предположению, называются однородными случайными полями в широком смысле. Поскольку далее будут рассматриваться только такие случайные поля, то слова «в широком смысле» будут, как правило, опускаться. Так как значение r(xi_(z),xi_(t))r\left(\xi_{z}, \xi_{t}\right) ковариационной функции однородного случайного поля зависит только от разности z-tz-t, то далее ковариация случайных величин xi_(z)\xi_{z} и xi_(t)\xi_{t} однородного случайного поля будет обозначаться cov(xi_(z+t),xi_(z))=r(t)\operatorname{cov}\left(\xi_{z+t}, \xi_{z}\right)=r(t).
Сделанные предположения позволяют установить следующие свойства ковариационной функции однородного случайного поля
Строгое неравенство r(0) > 0r(0)>0 имеет место только в том случае, когда xi_(z)\xi_{z} не является константой. Второе свойство следует также из определения
Для доказательства третьего свойства воспользуемся неравенством |E xi eta| <= E|xi eta||E \xi \eta| \leq E|\xi \eta| и неравенством Буняковского-Коши-Шварца E|xi eta| <= sqrt(E(xi)^(2)E(eta)^(2))E|\xi \eta| \leq \sqrt{E(\xi)^{2} E(\eta)^{2}}, доказательство которого приводится в 1.2.
Довольно часто при решении прикладных задач доступная информация об однородном случайном поле представлена набором его выборочных поверхностей. Ниже формулируется теорема, принадлежащая Слуцкому Е. Е. Она определяет условия, при выполнении которых среднее арифметическое значение, вычисленное по ограниченному фрагменту единственной выборочной поверхности, может использоваться в качестве оценки неизвестного среднего значения. Теорема была доказана Слуцким для стационарных в широком смысле случайных процессов. Предлагаемая ниже теорема (1.7.1) является ее естественным обобщением для случая, когда семейство случайных величин является однородным случайным полем.
Последовательность (xi_(n))_(n >= 1)\left(\xi_{n}\right)_{n \geq 1} случайных величин называется сходящейся к случайной величине xi\xi в среднеквадратическом, если числовая последовательность E(xi_(n)-xi)^(2)E\left(\xi_{n}-\xi\right)^{2} из средних значений сходится к нулю:
Далее такая сходимость будет обозначаться xi_(n)rarr xi\xi_{n} \rightarrow \xi в ср. кв.
Последовательность (xi_(n))_(n >= 1)\left(\xi_{n}\right)_{n \geq 1} случайных величин называется сходящейся к случайной величине xi\xi по вероятности, если для любого epsi > 0\varepsilon>0 числовая последовательность P(|xi_(n)-xi| <= epsi)P\left(\left|\xi_{n}-\xi\right| \leq \varepsilon\right) сходится к нулю
Такая сходимость (xi_(n))_(n >= 1)\left(\xi_{n}\right)_{n \geq 1} к xi\xi будет обозначаться xi_(n)rarr"P"xi\xi_{n} \xrightarrow{P} \xi.
Легко показать, что из сходимости xi_(n)rarr xi\xi_{n} \rightarrow \xi в ср. кв. следует сходимость xi_(n)rarr"P"xi\xi_{n} \xrightarrow{P} \xi по вероятности. В самом деле, применяя неравенство Чебышева к разности xi_(n)-xi\xi_{n}-\xi, получаем для любого epsi > 0\varepsilon>0 неравенство
Из сходимости xi_(n)rarr xi\xi_{n} \rightarrow \xi в ср. кв. следует, что lim_(n rarr+oo)E(xi_(n)-xi)^(2)=0\lim _{n \rightarrow+\infty} E\left(\xi_{n}-\xi\right)^{2}=0. Поэтому для любых delta > 0\delta>0 и epsi > 0\varepsilon>0 существует такое n(delta,epsi)n(\delta, \varepsilon), что E(xi_(n)-xi)^(2) < deltaepsi^(2)E\left(\xi_{n}-\xi\right)^{2}<\delta \varepsilon^{2} при n > n(delta,epsi),an> n(\delta, \varepsilon), \mathrm{a}
Это означает, что (xi_(n))_(n >= 1)\left(\xi_{n}\right)_{n \geq 1} сходится к xi\xi по вероятности. Отметим, что обратное утверждение неверно: из сходимости по вероятности не следует сходимость в ср. кв.
После замены события |xi_(n)-xi| > epsi\left|\xi_{n}-\xi\right|>\varepsilon из левой части последнего неравенства на противоположное |xi_(n)-xi| <= epsi\left|\xi_{n}-\xi\right| \leq \varepsilon следует неравенство
которое выполняется при любых n > n(delta,epsi)n>n(\delta, \varepsilon). Поэтому, если omega in Omega,x=xi(omega)\omega \in \Omega, x=\xi(\omega) и x_(n)=xi_(n)(omega)x_{n}=\xi_{n}(\omega) для всех n >= 1n \geq 1, то из него (неравенства) следует, что
Это неравенство допускает важную частотную интерпретацию. Оно означает, что при n > n(delta,epsi)n>n(\delta, \varepsilon) относительная частота события |x-x_(n)| <= epsi\left|x-x_{n}\right| \leq \varepsilon будет не меньше, чем 1-delta1-\delta. Однако, это не означает, что равенство lim_(n rarr+oo)x_(n)=x\lim _{n \rightarrow+\infty} x_{n}=x выполняется для всех omega in Omega\omega \in \Omega.
(1.7.1) Пусть (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} - однородное случайное поле со средним значением mm и ковариационной функцией r,A_(n)subZ^(2)r, A_{n} \subset Z^{2} - квадрат со стороной nn и x_(A_(n))x_{A_{n}} - изображение. Для того, чтобы последовательность m_(n)m_{n} случайных величин, определяемая равенством
По предположению m_(n)rarr mm_{n} \rightarrow m в ср. кв. при n rarr+oon \rightarrow+\infty. Поэтому для любого epsi > 0\varepsilon>0 существует n(epsi)n(\varepsilon) такой, что для всех n > n(epsi)n>n(\varepsilon) выполняется неравенство
Следствие. Если r(a)rarr0r(a) \rightarrow 0 при |a|=(a_(1)^(2)+a_(2)^(2))^((1)/(2))rarr+oo|a|=\left(a_{1}^{2}+a_{2}^{2}\right)^{\frac{1}{2}} \rightarrow+\infty, то
сходится в среднем квадратичном к mm при n rarr+oon \rightarrow+\infty.
Доказательство. Так как r(a)rarr0r(a) \rightarrow 0 при |a|rarr+oo|a| \rightarrow+\infty, то, для любого epsi > 0\varepsilon>0 существует такое a_(epsi)a_{\varepsilon}, что |r(a)| < epsi|r(a)|<\varepsilon при всех |a| > |a_(epsi)||a|>\left|a_{\varepsilon}\right|. Пусть
A_(n)(epsi)={a inA_(n):|a| > |a_(epsi)|}" и "M=max_(inA_(n)\\A_(n)(epsi))|r(a)|A_{n}(\varepsilon)=\left\{a \in A_{n}:|a|>\left|a_{\varepsilon}\right|\right\} \text { и } M=\max _{\in A_{n} \backslash A_{n}(\varepsilon)}|r(a)|
Определение статистической гипотезы. Примеры гипотез. Назначение выборки. Статистические критерии. Статистика для проверки гипотеза о виде распределения. Уровень значимости и критическая область.
Статистической гипотезой называется предположение о наличии у случайной величины или у нескольких случайных величин определенного свойства. Довольно часто проверяются гипотезы о виде распределения случайной величины, равенстве распределений двух и более случайных величин, об их независимости, а также гипотезы о свойствах числовых характеристик случайных величин. Для принятия гипотезы или отказа от нее используется информация о случайных величинах, содержащаяся в их выборках. Если выдвинутая гипотеза согласуется с информацией, содержащейся в выборках, то она принимается. В противном случае она отклоняется. Правило, в соответствии с которым гипотеза принимается или отвергается называется статистическим критерием. Одним из наиболее популярных статистических критериев является критерий, предложенный К. Пирсоном и получивший название chi^(2)\chi^{2} (хи квадрат). Ниже рассматривается пример его применения для проверки гипотезы о виде распределения случайной величины xi\xi. На основании исследования ее выборки (x_(j))_(1 <= j <= n)\left(x_{j}\right)_{1 \leq j \leq n} требуется подтвердить или отклонить предположение о том, что распределение случайной величины xi\xi является равномерным на интервале [a,b][\mathrm{a}, \mathrm{b}].
Проверка гипотезы начинается с разбиения интервала [a,b][a, b] точками (a_(j))_(1 <= j <= N+1),a=a_(1) < cdots < a_(N+1)=b\left(a_{j}\right)_{1 \leq j \leq N+1}, a=a_{1}<\cdots<a_{N+1}=b, на NN непересекающихся подинтервалов [a_(j),a_(j+1)[,1 <= j < N:}\left[a_{j}, a_{j+1}\left[, 1 \leq j<N\right.\right., и [a_(N),a_(N+1)]\left[a_{N}, a_{N+1}\right]. Затем для каждого подинтервала с левой границей a_(j)a_{j} определяется число n_(j)n_{j} элементов выборки, оказавшихся в нем. Очевидно, что должно выполняться равенство n_(1)+cdots+n_(N)=nn_{1}+\cdots+n_{N}=n. На следующем шаге для каждого подинтервала вычисляется вероятность p_(j),1 <= j <= Np_{j}, 1 \leq j \leq N, с которой случайная величина xi\xi принимает значение из [a_(j),a_(j+1)[:}\left[a_{j}, a_{j+1}[\right.. В соответствии с выдвинутой гипотезой ее распределение является равномерным на интервале [a,b][a, b]. Поэтому
p_(j)=P(a_(j) <= xi < a_(j+1))=(a_(j+1)-a_(j))/(b-a),1 <= j <= N.p_{j}=P\left(a_{j} \leq \xi<a_{j+1}\right)=\frac{a_{j+1}-a_{j}}{b-a}, 1 \leq j \leq N .
которая называется статистикой критерия. Она является случайной величиной. Доказано, что при верной гипотезе ее распределение стремится к распределению chi_(N-1)^(2)\chi_{N-1}^{2} с (N-1)(N-1) степенью свободы при n rarr+oon \rightarrow+\infty. Пусть alpha-\alpha- неотрицательное число, называемое уровнем значимости. Решая уравнение P(chi_(N-1)^(2) >= t_(alpha))=alphaP\left(\chi_{N-1}^{2} \geq t_{\alpha}\right)= \alpha, определяют неотрицательное число t_(alpha)t_{\alpha}. При значениях alpha\alpha близких к нулю (обычно alpha=0.001,0.01\alpha=0.001,0.01 или 0.05 ) событие chi_(N-1)^(2) >= t_(alpha)\chi_{N-1}^{2} \geq t_{\alpha} нас наблюдается редко. Поэтому интервал [t_(alpha),+oo[:}\left[t_{\alpha},+\infty[\right. часто называют критической областью. В соответствии с критерием хи квадрат для принятия гипотезы или ее отклонения требуется, используя выборку (x_(j))_(1 <= j <= n)\left(x_{j}\right)_{1 \leq j \leq n}, вычислить значение статистики X_(N-1)^(2)X_{N-1}^{2} и сравнить его с t_(alpha)t_{\alpha}. При наступлении события X_(N-1)^(2) < t_(alpha)X_{N-1}^{2}<t_{\alpha}, имеющую высокую вероятность ( 1-alpha1-\alpha ), гипотеза принимается. В противном случае, если произошло событие X_(N-1)^(2) >= t_(alpha)X_{N-1}^{2} \geq t_{\alpha} с низкой вероятностью alpha\alpha, гипотеза отклоняется.
Критерий хи квадрат следует применять в тех случаях, когда n >= 50n \geq 50, а n_(j) >= 5,1 <= j <= Nn_{j} \geq 5,1 \leq j \leq N. Для решения уравнения P(chi_(N-1)^(2) >= t_(alpha))=alphaP\left(\chi_{N-1}^{2} \geq t_{\alpha}\right)=\alpha использую таблицы распределения хи квадрат. Если число степеней свободы (N-1) > 30(N-1)>30, то вместо распределения хи квадрат используется нормальное. Его среднее значение и дисперсия оцениваются по выборке.
Изложенные выше сведения будут применяться в Главе 4 для выявления значимых локальных максимумов гистограммы амплитуд.
2.1 Определение локально однородной сцены
Определение объектов. Внутренние и граничные точки проекций. Изображения сцены и объекта. Свойства случайных величин, принадлежащих разным объектам. Определение простого объекта. Отличие сложного объекта от простого. Отличия их гистограмм.
Информация о сцене, как правило, носит не детерминированный, а статистический характер. Поэтому при создании модели сцены естественно воспользоваться теоретико-вероятностным подходом. Далее считается, что сцена является счетным множеством элементов, называемых пикселями. Каждый пиксель включает пару целых чисел z=(z_(1),z_(1))inZ^(2)z=\left(z_{1}, z_{1}\right) \in Z^{2}, которые называются его координатами, и дискретную случайную величину xi_(z)\xi_{z}. Все случайные величины (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} определены на одном и том же вероятностном пространстве (Omega,A,P)(\Omega, \mathcal{A}, P) и принимают значения из конечного множества Y={0,1,dots,|Y|-1}Y=\{0,1, \ldots,|Y|- 1\}. Таким образом, сцена является случайным полем. Пусть omega\omega - некоторое элементарное событие из Omega\Omega, а x_(z)=xi_(z)(omega)x_{z}=\xi_{z}(\omega) - значение случайной величины в z inZ^(2)z \in Z^{2}. Изображением сцены будет называться семейство x=(x_(z))_(z inZ^(2))x=\left(x_{z}\right)_{z \in Z^{2}}. Одним из примеров получения изображения сцены является регистрация отраженного или собственного электромагнитного излучения сцены в оптическом диапазоне с помощью оптико-электронной системы.
Пусть dd - евклидово расстояние на Z^(2)Z^{2}. Точки zz и tt из Z^(2)Z^{2} назовем соседями, если расстояние между ними равно единице: d(z,t)=1d(z, t)=1. Таким образом, у каждой точки четыре соседа. Расстоянием между конечными подмножествами AA и BB из Z^(2)Z^{2} назовем число d(A,B)d(A, B), определяемое равенством
d(A,B)=min_(a in A,b in B)d(a,b).d(A, B)=\min _{a \in A, b \in B} d(a, b) .
Точка aa, принадлежащая подмножеству AA из Z^(2)Z^{2}, будет называться граничной точкой AA, если у нее существует сосед zz из Z^(2)\\AZ^{2} \backslash A (не принадлежащий
A). Подмножество граничных точек множества AA называется его границей и обозначается Fr_(A)\operatorname{Fr}_{A} или Fr(A)\operatorname{Fr}(A). Остальные точки подмножества AA будут называться внутренними. Все соседи внутренних точек принадлежат AA. На рисунке 2.1.1 изображены три подмножества A,BA, B и CC. Их элементами являются пересечения прямых перпендикулярных линий. Подмножество AA содержит пять
Рисунок 2.1.1 - Внутренние и граничные точки множества
точек. Одна из них внутренняя, а четыре точки, обозначенные ромбами - граничные. Подмножество BB состоит из 16 внутренних и 20 граничных точек. Все четыре точки подмножества CC являются граничными. Очевидно, что само множество Z^(2)Z^{2} состоит только из внутренних точек.
Подмножество BB из Z^(2)Z^{2} назовем связным, если для любой пары точек zz и tt из BB существует конечное семейство (a_(j))_(1 <= j <= n)\left(a_{j}\right)_{1 \leq j \leq n} точек из BB таких, что z=a_(1)z=a_{1}, t=a_(n)t=a_{n} и d(a_(j),a_(j+1))=1,1 <= j < nd\left(a_{j}, a_{j+1}\right)=1,1 \leq j<n. Подмножества, приведенные на рисунке 2.1.1, являются связными. Однако подмножество, являющееся суммой ( A+BA+ B ), таковым не является. Подмножество AA будет называться односвязным, если его дополнение A^(C)=Z^(2)\\AA^{C}=Z^{2} \backslash A является связным.
Пусть AA - конечное односвязное подмножество Z^(2)Z^{2}. Семейство из |A||A| случайных величин xi_(A)=(xi_(a))_(a in A)\xi_{A}=\left(\xi_{a}\right)_{a \in A} будет называться простым объектом с проекцией AA, если оно является фрагментом некоторого однородного случайного поля со средним значением m_(A)m_{A} и ковариационной функцией r_(A)r_{A}. Поэтому среднее значение амплитуды и ее дисперсия у всех пикселей простого объекта одни и те же. Изображением простого объекта будет называться семейство x_(A)=(x_(z))_(z in A),x_(z)in Yx_{A}=\left(x_{z}\right)_{z \in A}, x_{z} \in Y. Примером изображения простого объекта можно считать изображение вертолета, представленное на рисунке 2.1.2. Характерным признаком простого объекта является его гистограмма с ярко выраженным единственным локальным максимумом, приведенная на рисунке 2.1.2.
Рисунок 2.1.2 - Простой объект
Рисунок 2.1.3 - Гистограмма простого объекта
Довольно часто при решении прикладных задач приходится иметь дело с объектами xi_(B)\xi_{B}, односвязная проекция BB которых является объединением из nn непересекающихся связных подмножеств (B_(j))_(1 <= j <= n)\left(B_{j}\right)_{1 \leq j \leq n}. При этом каждое семейство (xi_(B_(j)))_(1 <= j <= n)\left(\xi_{B_{j}}\right)_{1 \leq j \leq n} случайных величин является простым объектом со своим средним значением m_(B_(j))m_{B_{j}} и своей ковариационной функцией r_(B_(j))r_{B_{j}}. Такие объекты xi_(B)\xi_{B} будут называться составными или сложными объектами и обозначаться xi_(B)=(xi_(B_(j)),1 <= j <= n)\xi_{B}= \left(\xi_{B_{j}}, 1 \leq j \leq n\right). Если простые объекты xi_(B_(i))\xi_{B_{i}} и xi_(B_(j))\xi_{B_{j}}, входящие в сложный объект xi_(B)\xi_{B}, оказались соседями: d(B_(i),B_(j))=1d\left(B_{i}, B_{j}\right)=1, то соответствующие им однородные случайные поля должны отличаться хотя бы одним из указанных числовых параметров. Изображением x_(B)x_{B} сложного объекта является объединение изображений x_(B_(j))x_{B_{j}}, составляющих его простых объектов: x_(B)=(x_(B_(j)),1 <= j <= n)x_{B}=\left(x_{B_{j}}, 1 \leq j \leq n\right). В качестве примера изображения сложного объекта можно привести изображение легкового автомобиля на рисунке 2.1.4. Характерным признаком сложного объекта является присутствие у гистограммы его изображения, представленной на рисунке 2.1.5, двух и более локальных максимумов.
Рисунок 2.1.4 - Сложный объект
Рисунок 2.1.5 - Гистограмма сложного объекта
В частном случае объект может состоять только из одного пикселя. Такие объекты называются одноточечными.
Объекты xi_(A)\xi_{A} и xi_(B)\xi_{B} будут называться соседями, если d(A,B)=1d(A, B)=1. Предполагается, что проекции разных объектов не пересекаются. Если xi_(A)\xi_{A} и xi_(B)-\xi_{B}- разные объекты, то для любых a in Aa \in A и b in Bb \in B случайные величины xi_(a)\xi_{a} и xi_(b)\xi_{b} считаются независимыми. Объединение проекций всех объектов равняется Z^(2)Z^{2}. В теореме существования (2.2.1) из 2.2 будет доказано, что для задания сцен с перечисленными выше свойствами достаточно определить распределения вероятностей P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} только для ее объектов.
Сцена считается заданной, если известно разбиение Z^(2)Z^{2} на проекции образующих сцену простых объектов, а также если для каждого простого объекта с проекцией AA известно его среднее значение m_(A)m_{A} и ковариационная функция r_(A)r_{A}. Далее такие сцены будут называться локально однородными.
2.2 Теорема существования
Существование локально однородных сцен, сформулированное в предыдущем п. 2.2.1, доказывается в приводимой ниже теореме.
(2.2.1) Пусть на Z^(2)Z^{2} задано разбиение, состоящее из конечных попарно не пересекающихся подмножеств, называемых проекциями простых объектов, и пусть каждой проекции BB поставлено в соответствие распределение вероятностей P_(Y^(B))=(p_(Y^(B))(x_(B)))_(x_(B)inY^(B))P_{Y^{B}}=\left(p_{Y^{B}}\left(x_{B}\right)\right)_{x_{B} \in Y^{B}} на Y^(B)Y^{B}. Тогда существует вероятностное пространство ( Omega,A,P\Omega, \mathcal{A}, P ) и локально однородная сцена (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} на Z^(2)Z^{2} такая, что
P{omega in Omega:xi_(B)(omega)=x_(B)}=p_(Y^(B))(x_(B))P\left\{\omega \in \Omega: \xi_{B}(\omega)=x_{B}\right\}=p_{Y^{B}}\left(x_{B}\right)
для любой проекции BB и для любого x_(B)inY^(B)x_{B} \in Y^{B}. Кроме того, если AA и BB - проекции разных объектов сцены, то при любых a in Aa \in A и b in Bb \in B случайные величины xi_(a)\xi_{a} и xi_(b)\xi_{b} независимы:
Доказательство. В соответствии с теоремой Колмогорова [57], для задания случайного поля на Z^(2)Z^{2} необходимо и достаточно построить на Z^(2)Z^{2} семейство согласованных конечномерных распределений. В случае локально однородных сцен это можно сделать следующим образом.
Пусть AA - конечное подмножество Z^(2),(B_(j))_(j inJ_(A))Z^{2},\left(B_{j}\right)_{j \in J_{A}} - проекции простых объектов, такие, что
A subsum_(j inJ_(A))B_(j)" и "A nnB_(j)!=O/,j inJ_(A).A \subset \sum_{j \in J_{A}} B_{j} \text { и } A \cap B_{j} \neq \varnothing, j \in J_{A} .
Очевидно, что (A nnB_(j))subB_(j)\left(A \cap B_{j}\right) \subset B_{j}. Поставим в соответствие каждому подмножеству (A nnB_(j))\left(A \cap B_{j}\right) семейство P_(Y)P_{Y} AnB _(j)=(p_(Y):}_{j}=\left(p_{Y}\right. AnB {:_(j)(X_(A nnB_(j))))\left._{j}\left(X_{A \cap B_{j}}\right)\right) с помощью равенства
Определим семейство P_(Y^(A))=(p_(Y^(A))(x_(A)))_(x_(A)inY^(A))P_{Y^{A}}=\left(p_{Y^{A}}\left(x_{A}\right)\right)_{x_{A} \in Y^{A}} с помощью равенства
Для доказательства выполнения условий согласованности для семейства конечномерных распределений выберем множество CC на Z^(2)Z^{2}, не пересекающееся с AA. Для CC также существует, как и для AA, конечное семейство (B_(j))_(j inJ_(C))\left(B_{j}\right)_{j \in J_{C}} такое, что
Поэтому определим на Y^(C)Y^{C} распределение P_(Y^(C))=(p_(Y)c(x_(C)))_(x_(C)inY^(C))P_{Y^{C}}=\left(p_{Y} c\left(x_{C}\right)\right)_{x_{C} \in Y^{C}} указанным выше способом
Таким образом, если для каждого объекта xi_(B)\xi_{B} задано распределение вероятностей P_(Y^(B))=(p_(Y^(B))(x_(B)))_(x_(B)inY^(B))P_{Y^{B}}=\left(p_{Y^{B}}\left(x_{B}\right)\right)_{x_{B} \in Y^{B}}, то существует случайное поле (xi_(z))_(z inZ^(2))\left(\xi_{z}\right)_{z \in Z^{2}} такое, что
P{omega:(xi_(b)(omega),b in B)=x_(B)}=p_(Y^(B))(x_(B)).P\left\{\omega:\left(\xi_{b}(\omega), b \in B\right)=x_{B}\right\}=p_{Y^{B}}\left(x_{B}\right) .
Независимость случайных величин xi_(a)\xi_{a} и xi_(b)\xi_{b}, принадлежащих разным проекциям AA и BB, следует непосредственно из определения конечномерных распределений. Пусть D={a,b}D=\{a, b\}. Так как AA и BB проекции, то их пересечение является пустым множеством. Кроме того, D nn A={a},D nn B={b}D \cap A=\{a\}, D \cap B=\{b\} и D sub(A+B)D \subset (A+B). Поэтому
p_(Y^(D))(x_(D))=p_(Y^(D nn A))(x_(D nn A))p_(Y^(D nn B))(x_(D nn B))=p_(Y^({a}))(x_(a))p_(Y^({b}))(x_(b)).p_{Y^{D}}\left(x_{D}\right)=p_{Y^{D \cap A}}\left(x_{D \cap A}\right) p_{Y^{D \cap B}}\left(x_{D \cap B}\right)=p_{Y^{\{a\}}}\left(x_{a}\right) p_{Y^{\{b\}}}\left(x_{b}\right) .
Таким образом, теорема существования доказана. Из нее следует, что построение скалярной сцены, с формальной точки зрения, сводится к разбиению Z^(2)Z^{2} на конечные подмножества (проекции образующих ее простых объектов) и заданию для каждой проекции AA совместного распределения P_(Y)^(A)P_{Y}{ }^{A} на Y^(A)Y^{A}.
2.3 Примеры сцен и изображений
В настоящей работе будут использоваться три вида сцен и изображений. Сценами первого типа служат различные участки поверхности Земли. Их изображения формируются оптико-электронными системами (в том числе многоспектральными). Поэтому такие сцены и их изображения называются далее реальными. Очевидно, что предположения, использованные при построении любой математической модели, для реальных сцен в полном объеме не выполняются. Однако хорошая модель должна быть "снисходительной" к некоторым нарушениям предположений, которые использовались при ее построении. В противном случае применимость модели для решения прикладных задач, в частности прогнозирования, становится сомнительной. Реальные используются для оценки адекватности математических моделей.
В качестве примера фрагмента реальной сцены предлагается квадратный участок земной поверхности. Он порос травой, редким кустарником и отдельными деревьями. На нем присутствуют следы, оставленные колесными и гусеничными транспортными средствами. В центре участка присутствует массивный стальной объект длиной 6 и шириной 3 м. На рисунках 2.3.1-2.3.3 представлены три скалярных изображения описанного фрагмента размером 256 на 256 пикселей. Они получены оптико-электронной системой строчного типа с механическим сканированием, расположенной на летательном аппарате. Съемка проводилась в диапазоне [0.7;1.1][0.7 ; 1.1] мкм (рисунок 2.3.1), [3.0;5.0] мкм (рисунок 2.3.2) и [8.0;12.0] мкм (рисунок 2.3.3). По условиям съемки, длина стороны квадратного пикселя на местности должна равняться 0.3 м. На изображениях (в основном на третьем) заметны горизонтальные полосы. Эта особенность, называемая специалистами строчностью, характерна для изображений, формируемых первыми оптико-электронными системами строчного типа с механическим сканированием.
К сожалению, в ходе съемки с целью получения векторного (трехмер-
ного) изображения сцены не удалось обеспечить выполнение ряда важных требований. Например, для регистрации скалярных изображений, формируемых в трех спектральных зонах, над сценой приходилось пролетать два или три раза. Промежуток времени между следующими друг за другом пролетами равнялся нескольким минутам. Предполагалось, что за это время метеоусловия и состояние объектов, не успеют измениться. Из-за погрешностей бортовых высотомеров линейные размеры пикселей на местности получились разными. Поэтому размеры изображений одних и тех же объектов сцены на разных скалярных компонентах оказались различными. Более того, выполнить все полеты по одной и той же траектории не удалось. По этой причине скалярные изображения отличаются друг от друга величиной сдвига и поворота. Таким образом, для получения векторного (в данном случае трехмерного) изображения фрагмента сцены и его последующего использования в экспериментах по дешифрированию требуется предварительно привести скалярные компоненты к одному масштабу и выполнить их пространственное совмещение, включающее поворот и сдвиг. Необходимо отметить, что современное оборудование
Рисунок 2.3.1 - Первая компонента. Диапазон [0.7;1.1][0.7 ; 1.1] мкм
Рисунок 2.3.2 - Вторая компонента. Диапазон [3.0;5.0][3.0 ; 5.0] мкм
позволяет получать многоспектральные изображения, насчитывающие сотни компонент. Такие изображения получили название гиперспектральных.
Довольно часто в компьютерных экспериментах используются изображения реальных сцен после внесения в них тех или иных изменений. Такая модификация применяется, в частности, для добавления на изображение объектов, отсутствующих на исходном изображении. За свое сходство с реальными изображениями модифицированные изображения будут называться квазиреальными. В качестве примера на рисунках 2.3.4-2.3.6 приведены три квазиреальных изображения. Они получены в результате добавления изображений восьми дополнительных объектов, отсутствовавших сцене, с помощью компьютера на изображения, приведенные на рисунках 2.3.1-2.3.3. Изображения добавленных объектов имеют прямоугольную форму, случайные координаты и ориентацию. Их размеры совпадают с размерами реальных объектов. Предполагается, что каждый объект является фрагментом однородного случайного поля. В качестве средних значений и дисперсий добавленных объектов служат оценки соответствующих параметров, подсчитанные по реальным изображениям. Рядом с изображением каждого добавленного объекта указан его порядковый номер.
К третьему типу относятся локально однородные сцены с заранее заданными свойствами, которые используются для тестирования правильности работы алгоритмов. Их изображения строятся компьютерами. В качестве примера на рисунках 2.3.7, 2.3.8 и 2.3.9 приведены квадратные фрагменты со стороной 256 пикселей изображений однородных случайных полей. Они получены скользящим суммированием с hat(r)=0, hat(r)=1\hat{r}=0, \hat{r}=1 и hat(r)=2\hat{r}=2 соответственно. Каждый фрагмент состоит из семи объектов. Шесть объектов имеют прямоугольные проекции со сторонами 29 и 14 пикселей, случайную ориентацию и месторасположение. Пять из них присутствуют на приводимом фрагменте полностью. Шестой объект, находящийся у левого края фрагмента, присутствует частично. Остальные пиксели фрагмента образуют седьмой объект, ко-
торый по сложившейся среди специалистов по дешифрированию изображений традиции будет называться фоном. Признаком пикселя во всех экспериментах служила амплитуда со значениями из множества Y={0,dots,255}Y=\{0, \ldots, 255\}.
Рисунок 2.3.4 - Первая квазиреальная компонента
Рисунок 2.3.5 - Вторая квазиреальная компонента
Рисунок 2.3.6 - Третья квазиреальная компонента
Рисунок 2.3.7 - Изображение локально однородной сцены с взаимно независимыми случайными величинами
Рисунок 2.3.8 - Изображение локально однородной сцены, полученной скользящим суммированием с hat(r)=1\hat{r}=1
Рисунок 2.3.9 - Изображение локально однородной сцены, полученной скользящим суммированием с hat(r)=2\hat{r}=2
2.4 Сглаживание и шум
Определение и характеристики аддитивного шума. Измерение шума по изображению.
Каждый элемент матрицы ФПУ преобразует воздействующее на него электромагнитное излучение в цифровой электрический сигнал. Этот сигнал подвергается обязательному усилению, возможно, еще каким-либо заранее запланированным воздействиям и, наконец, устройством отображения (например, дисплеем) преобразуется в электромагнитное изучение видимого диапазона для визуального анализа или записывается на тот или иной носитель информации. К сожалению, в ходе своего «путешествия» по ОЭС кроме запланированных преобразований электрический сигнал испытывает также неконтролируемым воздействиям различных ее элементов. Совокупность таких воздействий, вызывающих изменения электрического сигнала, принято называть шумом.
Наиболее простым видом шума является аддитивны гауссовский шум. С формальной точки зрения такой шум является случайным полем. Образующие его случайные величины независимы в совокупности и имеют одно и то же нормальное распределение с нулевым средним и отличным от нуля среднеквадратическим отклонением. При использовании аддитивного гауссовского шума сцена xi=(xi_(z))\xi=\left(\xi_{z}\right) рассматривается в виде суммы двух неизвестных слагаемых. Одним слагаемым является детерминированная функция y=(y_(z))y=\left(y_{z}\right), описывающая свойства каждого пикселя сцены. Вторым слагаемым служит шум eta=(eta_(z))\eta=\left(\eta_{z}\right), который является случайным полем.
На рисунке 2.4.1 приведен фрагмент изображения, полученного камерой сотового телефона в темной комнате (при отсутствии какого-либо освещения), а на рисунке 2.4.2 - этот же фрагмент, но после линейного контрастирования.
Пуст rr - натуральное число, сглаживанием с радиусом rr изображения x_(D)=(x_(z))_(z in D)x_{D}=\left(x_{z}\right)_{z \in D} будет называться операция получения изображения hat(x)_(D)=( hat(x)_(z))_(z in D)\hat{x}_{D}= \left(\hat{x}_{z}\right)_{z \in D}, определяемая следующим образом
hat(x)_(z)=(1)/(|B(z,r)nn D|)sum_(t in B(z,r)nn D)x_(t),z in D.\hat{x}_{z}=\frac{1}{|B(z, r) \cap D|} \sum_{t \in B(z, r) \cap D} x_{t}, z \in D .
Изображение hat(x)_(D)\hat{x}_{D}, полученное в результате сглаживания, называется сглаженным.
Глава 3 ПРИЗНАКИ ОБЪЕКТОВ
Образующие сцену объекты могут отличаться довольно высоким разнообразием. При этом считается нормой, когда в изображениях разных объектов присутствуют пиксели с одинаковыми амплитудами. Это означает, что решение задачи обнаружения и классификации объектов только за счет использования амплитуд (иногда их называют прямыми признаками) является скорее исключением, а не нормой. Отдавая должное роли признаков, им уделяется отдельная глава.
В 3.1 обсуждается формальное определение признака объекта как отображения, заданного на множестве всех его изображений и удовлетворяющего некоторым естественным требованиям. Показывается, что класс таких отображений (признаков) достаточно широк.
При визуальном дешифрировании изображений форма присутствующих на сцене объектов является важным демаскирующим признаком, применяемым зачастую на подсознательном уровне. Для применение этого признака при автоматическом дешифрировании требуется его формальное определение. Несмотря на довольно большое число публикаций, посвященных изложению различных способов формализации понятия формы (см., например [49, 50, 6971]), исследования в этом направлении, по-прежнему, сохраняют свою актуальность. Этому признаку посвящается п. 3.2.
В п. 3.3 формулируется байесовская постановка задачи классификации объектов и вид оптимального решающего правила.
3.1 Формализация признаков
Определение признака. Примеры признаков: амплитуда пикселя, среднее арифметическое амплитуд проекции, площадь объекта.
Для каждого элементарного события omega in Omega\omega \in \Omega объект xi_(A)=(xi_(a))_(in A)\xi_{A}=\left(\xi_{a}\right)_{\in A} определяет с помощью равенства x_(a)=xi_(a)(omega),a in Ax_{a}=\xi_{a}(\omega), a \in A, изображение x_(A)=(x_(a))_(a in A)x_{A}=\left(x_{a}\right)_{a \in A}. Оно является элементом множества Y^(A)={(x_(a))_(a in A):x_(a)in Y}Y^{A}=\left\{\left(x_{a}\right)_{a \in A}: x_{a} \in Y\right\} всех возможных изображений объекта xi_(A)\xi_{A}. Следовательно, xi_(A)\xi_{A} является отображением типа Omega rarrY^(A)\Omega \rightarrow Y^{A}.
Для сравнения свойств различных объектов определим на множестве Y^(A)Y^{A} изображений каждого объекта xi_(A)\xi_{A} отображение f_(A):Y^(A)rarr Rf_{A}: Y^{A} \rightarrow R. Очевидно, что суперпозиция f_(A)@xi_(A)f_{A} \circ \xi_{A}, определяемая равенством (f_(A)@xi_(A))(omega)=f_(A)(xi_(A)(omega))\left(f_{A} \circ \xi_{A}\right)(\omega)=f_{A}\left(\xi_{A}(\omega)\right), является отображением типа Omega rarr R\Omega \rightarrow R. При теоретико-вероятностном подходе к задаче дешифрирования естественно потребовать, чтобы суперпозиция f_(A)@xi_(A)f_{A} \circ \xi_{A} была случайной величиной. Известно, что случайные величины образуют довольно широкий класс отображений. Вместе с тем, также известно, что не каждое отображение вида Omega rarr R\Omega \rightarrow R является случайной величиной. Что касается рассматриваемого случая, то ответ содержится в следующей теореме [67, с. 59].
(3.1.1) Если f_(A):R^(n)rarr Rf_{A}: R^{n} \rightarrow R является борелевским отображением, то суперпозиция f_(A)@xi_(A)f_{A} \circ \xi_{A} является случайной величиной на вероятностном пространстве ( Omega,A,P\Omega, \mathcal{A}, P ).
Доказательство. Пусть BB - борелевское подмножество из RR. Тогда его прообраз (f_(A)@xi_(A))^(-1)(B)\left(f_{A} \circ \xi_{A}\right)^{-1}(B) принимает вид
По условиям теоремы f_(A)^(-1)(B)f_{A}^{-1}(B) - борелевское подмножество в R^(|A|),xi_(A)-R^{|A|}, \xi_{A}- векторная ( |A||A| - мерная) случайная величина|. Поэтому xi_(A)^(-1)(f_(A)^(-1)(B))\xi_{A}^{-1}\left(f_{A}^{-1}(B)\right) из Omega\Omega является подмножеством A\mathcal{A}, а f_(A)@xi_(A)f_{A} \circ \xi_{A} - случайной величиной на ( Omega,A,P\Omega, \mathcal{A}, P ).
Далее борелевское отображение f_(A):R^(n)rarr Rf_{A}: R^{n} \rightarrow R, определенное на множестве Y^(A)Y^{A} изображений объекта xi_(A)\xi_{A}, будет называться его признаком, а распределение случайной величины f_(A)@xi_(A)-f_{A} \circ \xi_{A}- распределением признака f_(A)f_{A} с соответствующими средним значением, дисперсией и другими числовыми характеристиками. Известно (например, [XX]), что каждая непрерывная функция является борелевской. Поэтому класс возможных признаков достаточно широк. В частности, при A={z}A=\{z\} он включает тождественную функцию f_({z})(x_(z))=x_(z)f_{\{z\}}\left(x_{z}\right)=x_{z}. Так как f_({Z})@xi_({Z})=xi_({Z})f_{\{Z\}} \circ \xi_{\{Z\}}=\xi_{\{Z\}}, то каждая случайная величина xi_(z)\xi_{z} является признаком. Его значениями служат амплитуды x_(z)x_{z}, соответствующие различным omega in Omega\omega \in \Omega. В случае конечного подмножества AA признаками являются сумма и произведение
f_(A)(x_(A))=sum_(a in A)x_(a)" и "f_(A)(x_(A))=prod_(a in A)x_(a)f_{A}\left(x_{A}\right)=\sum_{a \in A} x_{a} \text { и } f_{A}\left(x_{A}\right)=\prod_{a \in A} x_{a}
а также отображение-константа f_(A)(x_(A))=c,c in Rf_{A}\left(x_{A}\right)=c, c \in R. Также, используя (3.1.1), легко убедиться, что признаками являются приведенные ниже отображения
f_(A)(x_(A))=(1)/(|A|)sum_(z in A)x_(z)" и "f_(A)(x_(A))=|A|.f_{A}\left(x_{A}\right)=\frac{1}{|A|} \sum_{z \in A} x_{z} \text { и } f_{A}\left(x_{A}\right)=|A| .
В первом случае значением признака является среднее арифметическое значение амплитуд изображения x_(A)x_{A}. Во втором случае значение признака равняется количеству элементов подмножества AA объекта, называемое обычно площадью его проекции. Она не зависит от амплитуд изображения x_(A)x_{A}. Такие признаки называются геометрическими.
Рассмотрим еще ряд часто используемых признаков, которые будут использоваться далее. Пусть BB - подмножество на RR, отображение I_(B):R rarr{0,1}I_{B}: R \rightarrow\{0,1\}, определяемое равенством
I_(B)(u)={[1",",u in B],[0",",u in R\\B],:}I_{B}(u)=\left\{\begin{array}{ll}
1, & u \in B \\
0, & u \in R \backslash B
\end{array},\right.
называется его индикатором. Для любого борелевского подмножества CC на RR его прообразом I_(B)^(-1)(C)I_{B}^{-1}(C) является одно из четырех борелевских подмножеств, указанных ниже
I_(B)^(-1)(C)={u in R:I_(B)(u)in C}={[B","quad1in C],[R\\B","quad0in C],[R","quad{0","1}sub C],[O/","quad R\\{0","1}].:}I_{B}^{-1}(C)=\left\{u \in R: I_{B}(u) \in C\right\}=\left\{\begin{array}{c}
B, \quad 1 \in C \\
R \backslash B, \quad 0 \in C \\
R, \quad\{0,1\} \subset C \\
\emptyset, \quad R \backslash\{0,1\}
\end{array} .\right.
Поэтому индикатор любого борелевского подмножества BB на RR является борелевским отображением.
Пусть xi_(A)-\xi_{A}- объект, x_(A)-x_{A}- его изображение, y in Yy \in Y - одно из возможных значений амплитуд, а n_(y)-n_{y}- количество пикселей изображения x_(A)x_{A}, амплитуды которых равны yy. В этом случае относительная частота n_(y)//|A|n_{y} /|A| амплитуды yy на изображении x_(A)x_{A} также является признаком. В самом деле, каждая амплитуда является борелевским подмножеством на RR, состоящим из одного элемента, а ее индикатор I_({y})I_{\{y\}} - борелевским отображением. Поэтому из (3.1.1) следует, что отображение f_(A)f_{A}, определяемое равенством
f_(A)(x_(A))=(1)/(|A|)sum_(a in A)I_({y})(x_(a))=(n_(y))/(|A|),f_{A}\left(x_{A}\right)=\frac{1}{|A|} \sum_{a \in A} I_{\{y\}}\left(x_{a}\right)=\frac{n_{y}}{|A|},
является борелевским отображением или признаком объекта xi_(A)\xi_{A}. Семейство (n_(y)//|A|)_(y in Y)\left(n_{y} /|A|\right)_{y \in Y} относительных частот, построенное по изображению x_(A)x_{A}, является его гистограммой. Гистограмма служит важной характеристикой изображения. Очевидно, что при перестановке местами любых пикселей изображения гистограмма остается прежней. Поэтому одной и той же гистограмме могут соответствовать разные по содержанию изображения.
Рассмотрим менее очевидную ситуацию, которая возникает при сравнении объектов, проекциями которых являются квадраты B(z,r)B(z, r) на Z^(2)Z^{2}. Предположим, что принятие некоторого решения зависит от результатов сравнения амплитуды x_(z)x_{z} центрального пикселя с амплитудами x_(t),t in B(z,r)\\{z}x_{t}, t \in B(z, r) \backslash\{z\}, остальных пикселей. Поэтому в качестве значения признака объекта xi_(B(z,r))\xi_{B(z, r)} удобно рассматривать количество точек из множества B(z,r)\\{z}B(z, r) \backslash\{z\}, для которых выполняется неравенство x_(z)-x_(t) > 0x_{z}-x_{t}>0. Интервала ]0,+oo[] 0,+\infty[ является борелевским подмножеством на RR, а его индикатор I_(]0,+oo)I_{] 0,+\infty} - борелевским отображением вида R rarr{0,1}R \rightarrow\{0,1\}. Из (3.1.1) следует, что отображение f_(B(z,r))f_{B(z, r)}, определяемое равенством
является борелевским, а значит признаком объекта xi_(B(z,r))\xi_{B(z, r)}.
Рассмотренные примеры позволяют надеяться, что отображения f_(A)f_{A}, определяемые на множестве Y^(A)Y^{A} изображений объекта xi_(A)\xi_{A}, при решении прикладных задач, в большинстве случаев окажутся действительно его признаками в смысле данного выше определения.
Довольно часто на множестве изображений объекта xi_(A)\xi_{A} приходится определять одновременно не один, а несколько признаков. В качестве примеров можно указать среднее значение и среднеквадратическое отклонение
m_(A)=(1)/(|A|)sum_(a in A)x_(a)" и "s_(A)^(2)=(1)/(|A|)sum_(a in A)(x_(a)-m_(A))^(2),m_{A}=\frac{1}{|A|} \sum_{a \in A} x_{a} \text { и } s_{A}^{2}=\frac{1}{|A|} \sum_{a \in A}\left(x_{a}-m_{A}\right)^{2},
а также гистограмму (n_(y)//|A|)_(y in Y)\left(n_{y} /|A|\right)_{y \in Y}.
3.2 Форма объекта
Форма является важным дешифровочным признаком. Несмотря на ее широкое применение при визуальной классификации, общепризнанного определения этого понятия не существует. В настоящей работе в качестве формы ограниченной фигуры на плоскости предлагается использовать распределение двумерной случайной величины (xi,eta)(\xi, \eta). Ее компонента xi\xi равняется числу хорд, вырезанных фигурой из проходящей через нее случайной прямой, а компонента eta\eta - их суммарной длине. Очевидно, что выпуклая фигура будет всегда вырезать из прямой только одну хорду. Этот случай представлен на рисунке 3.3.1 (случайные прямые выделены цветом). Количество хорд, вырезаемых невыпуклой фигурой из прямой, зависит от ее формы. Иллюстрирующий эту ситуацию случай представлен на рисунке 3.3.2. Доказано, что определенная таким образом форма плоской фигуры является инвариантом группы движений, то есть не зависит от параллельного переноса фигуры на произвольный вектор и поворота на произвольный угол.
Рисунок 3.3.1 - Выпуклая проекция
Рисунок 3.3.2 - Невыпуклая проекция
Считается, что фигуры AA и BB имеют одинаковую форму, если распределения P_(A)P_{A} и P_(B)P_{B} случайных величин ( xi_(A),eta_(A)\xi_{A}, \eta_{A} ) и ( xi_(B),eta_(B)\xi_{B}, \eta_{B} ) совпадают. Сравнение распределений P_(A)P_{A} и P_(B)P_{B} (формы двух проекций AA и BB ) удобно выполнять с помощью методов математической статистики. В самом деле, пусть n_(A)n_{A} и n_(B)n_{B} - количество случайных прямых, вырезанных проекциями AA и BB соответственно, и пусть (x_(j)^(A),y_(j)^(A))_(1 <= j <= n_(A))\left(x_{j}^{A}, y_{j}^{A}\right)_{1 \leq j \leq n_{A}} и (x_(j)^(B),y_(j)^(B))_(1 <= j <= n_(B))\left(x_{j}^{B}, y_{j}^{B}\right)_{1 \leq j \leq n_{B}} - соответствующие им двумерные выборки. Решение о равенстве двух распределений принимается в зависимости от результата проверки гипотезы однородности. Эта гипотеза является предположением о том, что двумерные случайные величины ( xi_(A),eta_(A)\xi_{A}, \eta_{A} ) и ( xi_(B),eta_(B)\xi_{B}, \eta_{B} ) имеют одно и то же распределение. Принятие гипотезы при заданном уровне значимости alpha\alpha означает, что распределения выборок совпадают, то есть обе проекции имеют одну и ту же форму. В противном случае (при отклонении гипотезы) принимается решение о том, что проекции имеют разную форму.
Очевидно, что по случайным причинам гипотеза может быть отклонена даже в случае совпадения формы сравниваемых фигур. Вероятность этого события равна alpha\alpha.
Классификация по форме выполняется в несколько этапов. Вначале по изображению сцены определяется проекция объекта. На следующем этапе форма полученной проекции сравнивается с формой проекций объектов каждого класса. Эти проекции строятся по 3d3 d моделям соответствующих объектов. Необходимо иметь в виду, что ориентация (направление наблюдения) распознаваемого объекта и масштаб изображения могут оказаться неизвестными. В этом случае для каждого класса необходимо предварительно подготовить наборы проекций, соответствующих разным масштабам и ориентациям образующих его объектов. Такой набор будет называться далее описанием класса. Решение о классе предъявленного объекта принимается на третьем этапе. Объект относится к тому классу, для которого количество совпадений формы проекции, построенной по изображению сцены, с формой проекций, составляющих описание класса, оказалось максимальным.
Обсуждение проверки гипотезы однородности начнем со случая, когда проекции являются выпуклыми: каждая вырезает из случайной прямой только одну хорду. Пусть AA и BB - сравниваемые фигуры, а n_(A)n_{A} и n_(B)n_{B} - количество независимых случайные прямых, пересекающих AA и BB соответственно. Пусть l_(A)=(l_(A,k))_(1 <= k <= n_(A))l_{A}= \left(l_{A, k}\right)_{1 \leq k \leq n_{A}} и l_(B)=(l_(B,k))_(1 <= k <= n_(B))l_{B}=\left(l_{B, k}\right)_{1 \leq k \leq n_{B}} - выборки длин хорд, вырезанных из этих прямых фигурами AA и BB. Предположение о равенстве распределений P_(A)P_{A} и P_(B)P_{B} в математической статистике называется гипотезой однородности. Для ее проверки разобьем множество RR вещественных чисел на ss интервалов. Пусть m_(A,j)m_{A, j} и m_(B,j)m_{B, j} - количество элементов выборок l_(A)l_{A} и l_(B)l_{B} соответственно, оказавшихся в jj-ом интервале. Известно [68, с. 483], что при равенстве P_(A)=P_(B)P_{A}=P_{B} распределение статистики X_(n_(A)+n_(B))^(2)X_{n_{A}+n_{B}}^{2} вида
стремиться к распределению chi^(2)\chi^{2} с (s-1)(s-1) степенью при (n_(A)+n_(B))rarr+oo\left(n_{A}+n_{B}\right) \rightarrow+\infty свободы. Поэтому вероятность оказаться в интервале [t,+oo[[t,+\infty[ для статистики X_(n_(A)+n_(B))^(2)X_{n_{A}+n_{B}}^{2} равняется приблизительно P(chi^(2) >= t)P\left(\chi^{2} \geq t\right).
Сказанное позволяет свести сравнение фигур по форме к проверке гипотезы однородности. В самом деле, зададим малое положительное число alpha\alpha (например, 0.01,0.0050.01,0.005 или 0.001 ) и, решив уравнение P(chi^(2) >= t_(alpha))=alphaP\left(\chi^{2} \geq t_{\alpha}\right)=\alpha относи-
тельно t_(alpha)t_{\alpha}, построим критическую область [t_(alpha),+oo[:}\left[t_{\alpha},+\infty[\right.. Далее вычисляется значение статистики X_(n_(A)+n_(B))^(2)X_{n_{A}+n_{B}}^{2} и сравнивается с t_(alpha)t_{\alpha}. Неравенство X_(n_(A)+n_(B))^(2) >= t_(alpha)X_{n_{A}+n_{B}}^{2} \geq t_{\alpha} означает, что произошло маловероятное (с вероятностью alpha\alpha ) событие. В этом случае гипотеза о равенстве распределений P_(A)P_{A} и P_(B)P_{B} отвергается. В противном случае гипотеза принимается. Очевидно, что вероятность отвергнуть верную гипотезу равняется alpha\alpha.
Наконец, перейдем к описанию формы невыпуклых фигур. Принципиальное отличие невыпуклой фигуры от выпуклой состоит в том, что она может вырезать из прямой нескольких отрезков, которые так же будут называться хордами. Следовательно, непосредственное применение предложенного выше определения формы для сравнения невыпуклых фигур не подходит. Поэтому каждой невыпуклой фигуре сопоставим не одну, а пару случайных величин. Первая случайная величина будет описывать число хорд, которые вырезает фигура из прямой линии. Вторая - общую длину всех хорд, вырезанных из прямой. Таким образом, форму невыпуклой фигуры можно рассматривать как распределение двумерной случайной величины. Две невыпуклые фигуры следует рассматривать как одинаковые по форме, если их распределения совпадают. Очевидно, что фигуры, получаемые друг из друга параллельным переносом или поворотом, будут иметь одну и ту же форму. Если применить определение формы невыпуклой фигуры для описания выпуклых фигур, то случайная величина, описывающая количество вырезанных хорд, будет принимать всегда (с вероятностью равной единице) значение 1. Это означает, что определение формы выпуклой фигуры является частным случаем определения формы невыпуклых фигур. Таким образом, для сравнения двух фигур по форме достаточно получить для каждой из них двумерную выборку и проверить гипотезу однородности...
3.3 Задача классификации объектов
Классификацией принято называть задачу об определении принадлежности объектов некоторого множества к одному из заранее определенных и непересекающихся подмножеств, называемых классами. Для ее решения используются характерные свойства (признаки) объектов. При этом предполагается, что сходство (измеряемое тем или иным способом) объектов, принадлежащих одному классу, должно быть выше, чем у объектов, принадлежащих разным классам. При числе классов, равным двум, классификация обычно называется обнаружением, а при числе классов равным числу объектов - идентификацией.
Введем терминологию, принятую в данной области исследований. Пусть Omega\Omega - множество объектов, разделенное на KK непересекающихся классов (Omega_(j))_(1 <= j <= K)\left(\Omega_{j}\right)_{1 \leq j \leq K}. Каждому объекту omega in Omega\omega \in \Omega соответствует vv-мерный вектор x=(x_(1),dots,x_(v))x= \left(x_{1}, \ldots, x_{v}\right) с вещественными координатами, который называется вектором признаков объекта omega\omega, а его координаты x_(j)x_{j} - признаками. Решение задачи классификации заключается в задании на множестве R^(v)R^{v}, состоящем из всех векторов признаков, отображения hh, называемого решающим правилом, которое каждому вектору признаков x inR^(v)x \in R^{v} ставит в соответствие номер h(x)h(x) класса, 1 <= h(x) <= K1 \leq h(x) \leq K, к которому следует отнести объект с признаком xx. Классификация объекта omega\omega из jj-ого класса Omega_(j)\Omega_{j} считается правильной, если h(x)=jh(x)=j. В противном случае классификация считается ошибочной.
Совокупность объектов, поступающих на классификацию, принято называть смесью. Смесь считается заданной, если выполняются два условия. Вопервых, для каждого класса Omega_(j)\Omega_{j} известна вероятность P(Omega_(j))P\left(\Omega_{j}\right) появления принадлежащих ему объектов в смеси. Она называется априорной вероятностью класса. Во-вторых, для каждого класса Omega_(j)\Omega_{j} известно распределение (например плотность p_(j)p_{j} ) признаков для образующих его объектов. В качестве количественной оценки эффективности классификации Байес предложил использовать вероятность правильной классификации объектов смеси (или вероятность ошибки классификации). Он же указал вид решающего правила, для которого эта вероятность является максимальной. Пусть xx - вектор признаков объекта omega\omega. В соответствии с теоремой Байеса объект omega\omega следует отнести к классу Omega_(k)\Omega_{k}, для которого неравенство
выполняется при любых j,1 <= j <= Kj, 1 \leq j \leq K. Такое решающее правило стало называться оптимальным.
При заданной смеси и выбранном решающем правиле можно вычислить вероятность e(h)e(h) правильной классификации объектов, образующих смесь. В случае известных плотностей она принимает вид
e(h)=sum_(j in K)P(Omega_(j))int_(h^(-1)({j}))p_(j)(x)dxe(h)=\sum_{j \in K} P\left(\Omega_{j}\right) \int_{h^{-1}(\{j\})} p_{j}(x) d x
Если признаки являются дискретными случайными величинами, то
К сожалению, при решении прикладных задач сведения об априорных вероятностях классов и распределениях признаков в них часто отсутствуют. Поэтому применить оптимальное правило не удается.
На рисунках 3.3.1 и 3.3.2 приведены два примера геометрической интерпретации теоремы Байеса для случая двух классов и одного признака. Из-за отсутствия у текстового редактора греческого алфавита на рисунках вместо буквы «Ω» в обозначениях классов используется буква «О».
Рисунок 3.3.1
Рисунок 3.3.2
При значении признака x < x_(0)x<x_{0} выполняется неравенство P(Omega_(1))p_(1)(x) > P(Omega_(2))p_(2)(x)P\left(\Omega_{1}\right) p_{1}(x)> P\left(\Omega_{2}\right) p_{2}(x). В соответствии с теоремой Байеса решение принимается в пользу первого класса. Поэтому все объекты второго класса, у которых x < x_(0)x<x_{0}, классифицируются неверно. Для x > x_(0)x>x_{0} имеет место противоположное неравенство P(Omega_(1))p_(1)(x) < P(Omega_(2))p_(2)(x)P\left(\Omega_{1}\right) p_{1}(x)<P\left(\Omega_{2}\right) p_{2}(x). Поэтому решение принимается в пользу второго класса. Следовательно все объекты первого класса, у которых x > x_(0)x>x_{0}, классифицируются неверно. При x=x_(0)x=x_{0} имеет место равенство P(Omega_(1))p_(1)(x)=P\left(\Omega_{1}\right) p_{1}(x)= P(Omega_(2))p_(2)(x)P\left(\Omega_{2}\right) p_{2}(x). Поэтому объект можно отнести к любому классу. Из сравнения рисунков следует, что число неверных классификаций в случае, представленном на рисунке 3.3.2, значительно больше, чем в случае с рисунка 3.3.1.
Глава 4 СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЙ
Форма проекции объекта на плоскость перпендикулярную направлению наблюдения является важным демаскирующим признаком. Очевидно, что площадь, периметр и другие свойства проекции также, как и ее форма, могут использоваться в качестве признаков объекта, которые называются геометрическими. Для того, чтобы ими воспользоваться, требуется построить проекцию объекта по изображению сцены. Задача, состоящая в определении проекций объектов, присутствующих на сцене, по ее изображению будет называться далее сегментацией. Результат ее решения можно наглядно представить в виде специализированного изображения (карты). На ней пиксели каждой проекции имеют одну и ту же амплитуду, называемую псевдоцветом.
Довольно часто изображения используются для выявления на сцене объектов определенного типа. Решением такой задачи, называемой обнаружением объектов, является набор координат всех обнаруженных объектов. При этом в качестве координат объекта могут рассматриваться, например, координаты центра прямоугольника со сторонами параллельными сторонам изображения, описанного вокруг его проекции. При отсутствии сведений о местонахождении объектов приходится проводить обнаружение в каждом месте сцены, где они могут находится. Если известен масштаб изображения, то на нем можно указать семейство квадратных фрагментов, удовлетворяющих двум свойствам. Во-первых, для любого объекта, присутствующего на сцене, существует хотя бы один фрагмент, содержащий его проекцию. Во-вторых, все точки проекции являются внутренними точками квадратного фрагмента. Фрагменты с такими свойствами будут называться далее зонами интереса. Из сказанного следует, что обнаружение присутствующих на сцене объектов сводится к заданию на изображении семейства квадратных фрагментов и решению задачи обнаружения в каждом из них. Пиксели зоны интереса, не принадлежащие объекту, часто называются его окружением или фоном. Он может оказаться простым фрагментом однородного случайного поля или сложным. В последнем случае он состоит из фрагментов разных однородных случайных полей.
4.1 Зоны интереса
Квадратом на Z^(2)Z^{2} с верхней левой вершиной в точке c=(c_(1),c_(2))inZ^(2)c=\left(c_{1}, c_{2}\right) \in Z^{2} и стороной из ll пикселей назовем подмножество Q(c)subZ^(2)Q(c) \subset Z^{2}, определяемое равенством
Вершина квадрата может не указываться в тех случаях, когда это не приводит
к неопределенности.
Пусть QQ - квадрат. Семейство xi_(Q)=(xi_(z))_(z in Q)\xi_{Q}=\left(\xi_{z}\right)_{z \in Q} случайных величин будет называться зоной интереса объекта xi_(A)\xi_{A}, если, выполняются два следующих условия. Во-первых, проекция AA объекта состоит только из внутренних точек квадрата Q:A sub Q\\Fr_(Q)Q: A \subset Q \backslash F r_{Q}. Во-вторых, среди остальных пикселей xi_(Q\\A)\xi_{Q \backslash A} зоны интереса отсутствуют пиксели, принадлежащие другим объектам того же типа, что и xi_(A)\xi_{A}. Совокупность xi_(Q\\A)\xi_{Q \backslash A} остальных пикселей зоны интереса будет называться окружением объекта xi_(A)\xi_{A} или его фоном.
Пусть xi_(A)\xi_{A} - объект, число D(A)D(A), определяемое равенством
D(A)=max_(a in A,b in A)d(a,b)D(A)=\max _{a \in A, b \in A} d(a, b)
назовем диаметром объекта xi_(A)\xi_{A}. Вместо D(A)D(A) может использоваться короткое обозначение DD, если это не приводит к неопределенности. Если xi_(Q)\xi_{Q} - зона интереса объекта xi_(A)\xi_{A} с диаметром DD, то для стороны ll квадрата QQ должно выполняться неравенство l >= D+2l \geq D+2. В самом деле, если ( c_(1),c_(2)c_{1}, c_{2} ) - координаты левой верхней вершины квадрата, то ( c_(1)+l,c_(2)c_{1}+l, c_{2} ) - координаты его правой верхней вершины. Поэтому для любых точек aa и bb проекции AA должно выполняться неравенство d(a,b) <= Dd(a, b) \leq D. Поскольку AA состоит из внутренних точек, то l >= D+2l \geq D+2. Очевидно, что у объекта может быть несколько зон интереса.
В качестве обоснования целесообразности введения понятия зоны интереса приведем следующие соображения, которые будут использоваться далее. Пусть x_(Q)=(x_(z))_(z in Q)x_{Q}=\left(x_{z}\right)_{z \in Q} - изображение зоны интереса xi_(Q)\xi_{Q} объекта xi_(A)\xi_{A}. Из ее определения следует, что пиксели xi_(Fr(Q))\xi_{F r(Q)} границы зоны интереса не принадлежат самому объекту xi_(A)\xi_{A}. Поэтому изображение (x_(Z))_(Z in Fr(Q))\left(x_{Z}\right)_{Z \in F r(Q)} границы позволяют получить сведения о свойствах амплитуд пикселей из окружения объекта. Эти сведения могут использоваться для классификации по амплитуде внутренних пикселей зоны интереса на два класса с условными названиями «Объект» и «Фон». Для этого амплитуда x_(z)x_{z} каждого внутреннего пикселя z in Q\\Fr_(Q)z \in Q \backslash F r_{Q} зоны интереса сравнивается тем или иным способом с амплитудами (x_(z))_(z in Fr(Q))\left(x_{z}\right)_{z \in F r(Q)} пикселей границы. В случае сходства пиксель относится к классу Фон. В противном случае пиксель относится к классу Объект. Полученная в результате сегментации проекция объекта используется далее для его классификации. Как правило, в зоне интереса присутствуют пиксели с одинаковой амплитудой, но принадлежащие объекту и фону. Их появление приводит к неизбежным ошибкам сегментации. Для снижения числа ошибок при сегментации следует использовать дополнительные признаки кроме амплитудных. В приводимой ниже теореме перечисляются требования к квадратам, гарантирующие выполнение первого условия, сформулированного в определении зоны интереса.
(4.1.1) Пусть xi_(A)\xi_{A} - объект, DD - его диаметр, ll - целое число такое, что l >= (D+2)l \geq (D+2), и Delta\Delta - целое число, удовлетворяющий неравенству 0 < Delta < (l-D)0<\Delta<(l-D). Тогда среди всех квадратов со стороной ll и вершинами в точках (m Delta,n Delta),m in Z(m \Delta, n \Delta), m \in Z
и n in Zn \in Z, найдется хотя бы один такой квадрат QQ, что все точки проекции AA окажутся его внутренними точками: A sub Q\\Er_(Q)A \subset Q \backslash E r_{Q}.
Доказательство. В частном случае, когда l=D+2l=D+2, а Delta=1\Delta=1, утверждение теоремы очевидно. Рассмотрим общий случай. Пусть a_(1)inZ^(2)a_{1} \in Z^{2} - горизонтальная координата самого левого пикселя и a_(2)inZ^(2)a_{2} \in Z^{2} - вертикальная координата самого верхнего пикселя проекции AA. По условию теоремы Delta > 0\Delta>0. Поэтому существуют целые числа q_(1)q_{1} и q_(2)q_{2} такие, что выполняются неравенства
Пусть b_(1)inZ^(2)b_{1} \in Z^{2} - горизонтальная координата самого правого пикселя, а b_(2)inZ^(2)b_{2} \in Z^{2} - вертикальная координата самого нижнего пикселя проекции AA. Так как DD - диаметр, то b_(1)-a_(1) <= Db_{1}-a_{1} \leq D и b_(2)-a_(2) <= Db_{2}-a_{2} \leq D. Поэтому
b_(1) <= a_(1)+D," a "b_(2) <= a_(2)+Db_{1} \leq a_{1}+D, \text { a } b_{2} \leq a_{2}+D
Используя выше полученные оценки для a_(1)a_{1} и a_(2)a_{2}, имеем
b_(1) <= q_(1)+Delta+D" и "b_(2) <= q_(2)+Delta+D.b_{1} \leq q_{1}+\Delta+D \text { и } b_{2} \leq q_{2}+\Delta+D .
По предположению теоремы Delta < (l-D)\Delta<(l-D). Следовательно,
b_(1) < q_(1)+l" и "b_(2) < q_(2)+l.b_{1}<q_{1}+l \text { и } b_{2}<q_{2}+l .
Пусть Q(q)Q(q) - квадрат со стороной ll и вершиной в точке q=(q_(1),q_(2))q=\left(q_{1}, q_{2}\right). Точки a=(a_(1),a_(2))a=\left(a_{1}, a_{2}\right) и b=(b_(1),b_(2))b=\left(b_{1}, b_{2}\right) являются его внутренними точками по построению. Легко проверить, что проекция AA принадлежит квадрату вершиной aa и стороной max{(b_(2)-a_(2)),(b_(1)-a_(1))}\max \left\{\left(b_{2}-a_{2}\right),\left(b_{1}-a_{1}\right)\right\}, состоящего из внутренних точек QQ. Таким образом, теорема доказана.
Второе условие из определения зоны интереса запрещает присутствие в ней пикселей других объектов. Очевидно, что оно выполняется, если расстояние между объектами превышает некоторое минимальное значение.
Пусть xi_(Q)\xi_{Q} - зона интереса объекта xi_(A)\xi_{A}, в соответствии со вторым условием ее определения в xi_(Q\\A)\xi_{Q \backslash A} объекта должны отсутствовать пиксели других объектов того же типа. Это ...
Теорема 4.1.2. Пусть DD - диаметр объекта xi_(A),d,d > 1,-\xi_{A}, d, d>1,- минимальное расстояние между такими объектами, а QQ - квадрат со стороной ll, такой, что A sub Q\\Er(Q)A \subset Q \backslash E r(Q). Если l <= (D+2d)l \leq(D+2 d), то QQ является зоной интереса для xi_(A)\xi_{A}.
Доказательство. Существует квадрат со стороной DD, содержащий проекцию AA.
Это условие выполняется, если расстояние между объектами, которые требуется обнаружить, больше (lsqrt2)//2(l \sqrt{2}) / 2 пикселей. В этом случае обнаружение достаточно провести только среди всех квадратов со стороной ll и вершинами
в точках (m Delta,n Delta),m in Z(m \Delta, n \Delta), m \in Z и Z in RZ \in R.
Пусть hh и ww - натуральные числа, CC - прямоугольник на Z^(2)Z^{2} с высотой hh и шириной ww, определяемый равенством
а x_(C)x_{C} - изображение из hh строк и ww столбцов некоторого участка сцены. При отсутствии сведений о местонахождении и ориентации объектов на сцене приходится проводить их обнаружение во всех местах сцены, где они могут находится, то есть выполнять поиск. Для этого по известному диаметру DD объектов выбирается сторона l >= (D+2)l \geq(D+2) зоны интереса, величина Delta < (l-D)\Delta<(l-D) и проводится обнаружение только в тех квадратах с вершинами (m Delta,n Delta)in C(m \Delta, n \Delta) \in C и стороной ll, которые принадлежат CC. Очевидно, что координаты mm и nn их вершин должны удовлетворять следующим неравенствам
0 <= m Delta <= (h-l)Delta" и "0 <= n Delta <= (w-l)Delta". "0 \leq m \Delta \leq(h-l) \Delta \text { и } 0 \leq n \Delta \leq(w-l) \Delta \text {. }
Пусть [x][x] - целая часть числа xx, тогда количество NN таких квадратов равняется
С увеличением Delta\Delta количество квадратов убывает со скоростью (1//Delta)^(2)(1 / \Delta)^{2}. С другой стороны, рост ll также уменьшает NN и одновременно приводит к увеличению окрестности проекции. Это может усложнить сегментацию увеличенной зоны интереса. Если в ходе увеличения размеров в квадрате xi_(A)\xi_{A} появятся пиксели других объектов такого же типа, то он (квадрат) перестанет быть зоной интереса.
4.2 Сегментация простых зон интереса
Далее будут рассматриваться зоны интереса двух типов. Зона интереса xi_(Q)\xi_{Q} будет называться простой, если находящийся в ней объект xi_(A)\xi_{A} и его окрестность xi_(Q\\A)\xi_{Q \backslash A} являются фрагментами разных однородных случайных полей. При этом случайное поле со средним значением m_(A)m_{A} и корреляционной функцией r_(A)r_{A} описывает свойства объекта, а случайное поле со средним значением m_(Q\\A)m_{Q \backslash A} и корреляционной функцией r_(Q\\A)r_{Q \backslash A} описывает свойства его окрестности. Признаком простой зоны интереса служит присутствие на гистограмме амплитуд зоны интереса, построенной по ее изображению, как правило, двух явно выраженных локальных максимумов, соответствующих объекту и фону. В качестве иллюстрации сказанного на рисунке 4.2.1 приведен фрагмент реального изображения с выбранной на нем зоной интереса, а на рисунке 4.2.2 - соответствующая ей гистограмма. Важно отметить, что фактическое количество локальных максимумов на гистограмме намного больше двух. Все локальные максимумы, кроме двух, вызваны случайными изменениями амплитуд и поэтому будут называться ложными. Локальные максимумы, соответствующие объекту (значение амплитуды 96) и фону (значение амплитуды 192), будут называться реальными максимумами. Вопрос о том, как отличать ложные локальные максимумы от реальных будет подробно обсуждаться далее в п.4.4.
Рисунок 4.2.1 - Зона интереса
Рисунок 4.2.2 - Гистограмма зоны интереса
Пусть x_(Q)x_{Q} - изображение простой зоны интереса xi_(Q)\xi_{Q} с объектом xi_(A)\xi_{A} и его окрестности xi_(Q\\A)\xi_{Q \backslash A}. Ее сегментация заключается в разделении (классификации) пикселей, образующих xi_(Q)\xi_{Q}, на два класса с условными названиями «Объект» и «Фон» по ее изображению x_(Q)x_{Q}. Как правило, информация о средних значениях m_(A)m_{A} и m_(Q\\A)m_{Q \backslash A} объекта и фона, а также их корреляционных функциях r_(A)r_{A} и r_(Q\\A)r_{Q \backslash A} отсутствует. Однако, из определения зоны интереса следует, что пиксели, образующие ее границу xi_(Fr(Q))\xi_{F r(Q)}, принадлежат фону. Поэтому изображение x_(Fr(Q))x_{F r(Q)} границы может использоваться для вычисления оценок bar(x)_(Q\\A)\bar{x}_{Q \backslash A} и s_(Q\\A)s_{Q \backslash A} неизвестных среднего значения m_(Q\\A)m_{Q \backslash A} и среднеквадратического отклонения sigma_(Q\\A)\sigma_{Q \backslash A} фона соответственно:
bar(x)_(Q\\A)=(1)/(|Fr(Q)|)sum_(z in Fr(Q))x_(z),quads_(Q\\A)=((1)/(|Fr(Q)|)sum_(z in Fr(Q))(x_(z)- bar(x)_(Q\\A))^(2))^(1//2)\bar{x}_{Q \backslash A}=\frac{1}{|F r(Q)|} \sum_{z \in F r(Q)} x_{z}, \quad s_{Q \backslash A}=\left(\frac{1}{|F r(Q)|} \sum_{z \in F r(Q)}\left(x_{z}-\bar{x}_{Q \backslash A}\right)^{2}\right)^{1 / 2}
Пусть eta\eta - случайная величина со средним значением m_(eta)m_{\eta} и СКО sigma_(eta)\sigma_{\eta}. Неравенство Чебышева
P(|eta-m_(eta)| <= ksigma_(eta)) >= 1-(1)/(k^(2)),P\left(\left|\eta-m_{\eta}\right| \leq k \sigma_{\eta}\right) \geq 1-\frac{1}{k^{2}},
позволяет определить интервал [m_(eta)-ksigma_(eta),m_(eta)+ksigma_(eta)]\left[m_{\eta}-k \sigma_{\eta}, m_{\eta}+k \sigma_{\eta}\right], в который с заданной вероятностью pp попадают значения случайной величины eta\eta. В самом деле, пусть p,0 < p < 1p, 0<p<1. Приравняв правую часть неравенства Чебышева к pp, получаем уравнение 1-(1)/(k^(2))=p1-\frac{1}{k^{2}}=p относительно kk. Его решением является k=1//(1-p)^(1//2)k=1 / (1-p)^{1 / 2}, при котором в указанный выше интервал попадают 100 p%100 p \% значений случайной величины eta\eta. После замены неизвестных m_(Q\\A)m_{Q \backslash A} и sigma_(Q\\A)\sigma_{Q \backslash A} их оценками, интервал принимает вид
Для завершения сегментации осталось выбрать достаточно большое значение pp, чтобы в интервале оказались почти все амплитуды фона, и проверить попадание в этот интервал амплитуд (x_(z))_(z in Q\\Fr(Q))\left(x_{z}\right)_{z \in Q \backslash F r(Q)} всех внутренних пикселей зоны интереса. Если амплитуда x_(z)x_{z} попала в интервал, то пиксель с координатой zz относится к классу Фон. В противном случае, если амплитуда x_(z)x_{z} оказалась вне интервала, принимается решение о недостаточном ее сходстве с амплитудами пикселей фона. Поэтому такой пиксель следует отнести к классу Объект. Напомним, что по определению зоны интереса пиксели (xi_(z))_(z in Fr(Q))\left(\xi_{z}\right)_{z \in F r(Q)}, образующие ее границу, принадлежат классу Фон.
Амплитуды пикселей являются случайными величинами. Поэтому амплитуда x_(z)x_{z} пикселя из окрестности объекта может оказаться вне указанного интервала. В этом случае пиксель фона с координатой ZZ в соответствии с принятым решающим правилом будет ошибочно отнесен к классу Объект. Вероятность такого события равняется ( 1-p1-p ).
В 2.4 предлагалось считать амплитуду каждого пикселя суммой двух слагаемых: сигнала и шума. Там же показано, что сглаживание исходного изображения с использованием квадратной окрестности с радиусом hat(r)\hat{r} уменьшает шум на сглаженном изображении в (2 hat(r)+1)(2 \hat{r}+1) раз. На рисунках 4.2.3 и 4.2.4 приведены результаты сегментации зоны интереса с рисунка 4.2.1. В первом случае сегментации подверглось исходное изображение (без сглаживания). Во втором случае перед сегментацией изображение было сглажено с радиусом hat(r)=1\hat{r}=1.
Результатом сегментации простой зоны интереса должны быть два связных подмножества: проекция AA самого объекта и проекция Q//AQ / A его окрестности (или фона). Однако, из-за шума и присутствия в зоне интереса пикселей с одинаковыми амплитудами, принадлежащими как объекту, так и фону, в ходе
Рисунок 4.2.3 - Сегментация исходного изображения (без сглаживания)
Рисунок 4.2.4 - Сегментация сглаженного изображения ( r=1r=1 )
сегментации возникают ошибки. Проекция объекта может увеличиться за счет присоединения некоторых пикселей фона, амплитуды которых оказались вне интервала. Также, она может лишиться части собственных пикселей, если их амплитуды попали в интервал. Поэтому результатом сегментации будут, как правило, два множества hat(A)\hat{A} и Q\\ hat(A)Q \backslash \hat{A}, отличные от фактических AA и Q//AQ / A. При этом одно из них или оба могут состоять из нескольких изолированных связных подмножеств (компонент). Из определения зоны интереса следует, что в ней может находится только один объект и фон. Поэтому необходимо провести дополнительную операцию - коррекцию результата сегментации. Для этого используются дополнительные признаки, к которым относятся площадь, габаритные размеры, форма, связность проекций объектов и другие. В рассмотренном примере коррекция не проводилась.
4.3 Сегментация сложной зоны интереса
Очевидно, что составным или сложным может быть не только объект, но и фон в зоне интереса. В связи с этим зона интереса будет называться составной или сложной, если составным является или объект или фон, а также, если составными являются одновременно они оба. Исходной информацией о зоне интереса xi_(Q)\xi_{Q} с объекта xi_(A)\xi_{A} служит ее изображение x_(Q)=(x_(z))_(z in Q)x_{Q}=\left(x_{z}\right)_{z \in Q}. Для каждого значения амплитуды y in Yy \in Y по изображению x_(Q)x_{Q} можно подсчитать количество n_(y)n_{y} пикселей зоны интереса, амплитуды которых совпадают с этим значением. Оно будет называться повторяемостью значения yy в отличие от его относительной частоты (n_(y)//|Q|)_(y in Y)\left(n_{y} /|Q|\right)_{y \in Y}. Иногда, когда это не приводит к неопределенности, семейство повторяемостей (n_(y))_(y in Y)\left(n_{y}\right)_{y \in Y} будет также называется гистограммой изображения.
Для сегментации сложных зон интереса предлагается воспользоваться следующими соображениями. Во-первых, предполагается, что на гистограмме зоны интереса для каждого простого объекта, включая фон, должен присутствовать свой локальный максимум. Каждый локальный максимум соответствует фрагменту однородного случайного поля, описывающего составную часть сложного объекта или составную часть фона. При этом точка максимума является амплитудой, совпадающей со средним значением соответствующего фрагмента однородного случайного поля. В случае сложной зоны интереса их на гистограмме должно быть не менее трех. Во-вторых, также предполагается, что амплитуды пикселей каждого объекта группируются вокруг точки, соответствующей его локальному максимуму. Поэтому для разделения амплитуд, оказавшихся между соседними локальными максимумами (левым и правым) предлагается использовать точку наименьшего локального минимума, находящегося между ними. Пиксели с амплитудами, оказавшимися слева от точки минимума, предлагается считать принадлежащими объекту, которому соответствует левый локальный максимум. Пиксели с амплитудами, оказавшимися справа от точки минимума, предлагается считать принадлежащими объекту, которому соответствует правый локальный минимум. Пиксели, амплитуда которых совпала с амплитудой точки минимума, могут быть отнесены к любому из указанных объектов.
Признаком составной зоны интереса является гистограмма с тремя и более реальными локальными максимумами. По-видимому, наиболее легкой, с точки зрения сегментации, является зона интереса, содержащая простой объект и сложный фон. Пример реального изображения с такой зоной и ее гистограмма представлены на рисунках 4.3.1 и 4.3.2 соответственно. Составляющие зону интереса пиксели образуют прямоугольник с выделенной границей. Визуальный анализ изображения зоны интереса позволяет без труда убедиться в том, что фон объекта состоит из трех фрагментов, амплитуды которых отличаются средними значениями. Этот вывод подтверждается и гисто-
граммой. Следует обратить внимание на ряд отдельных пикселей, находящихся возле левой вертикальной границы зоны, амплитуды которых заметно отличаются от амплитуд своих соседей, что свидетельствует о повреждении соответствующих элементов матрицы ФПУ.
На рисунках 4.3.3 и 4.3.4 приведены изображение с зоной интереса со сложным объектом и простым фоном, а также ее гистограмма. Изображение объекта позволяет уверено утверждать, что он является сложным: состоит из нескольких фрагментов однородных случайных полей с разными средними значениями. Что подтверждается гистограммой.
Рисунок 4.3.3 - Зона интереса со сложным объектом
Рисунок 4.3.4 - Гистограмма зоны интереса со сложным объектом
https://cdn.mathpix.com/cropped/eb530be6-5346-4fc5-8ad9-46eb76334cd8-77.jpg?height=314&width=300&top_left_y=1589&top_left_x=497 https://cdn.mathpix.com/cropped/eb530be6-5346-4fc5-8ad9-46eb76334cd8-77.jpg?height=468&width=782&top_left_y=1511&top_left_x=1118
Рисунок 4.3.3 - Зона интереса со сложным объектом Рисунок 4.3.4 - Гистограмма зоны интереса со сложным объектом|  | 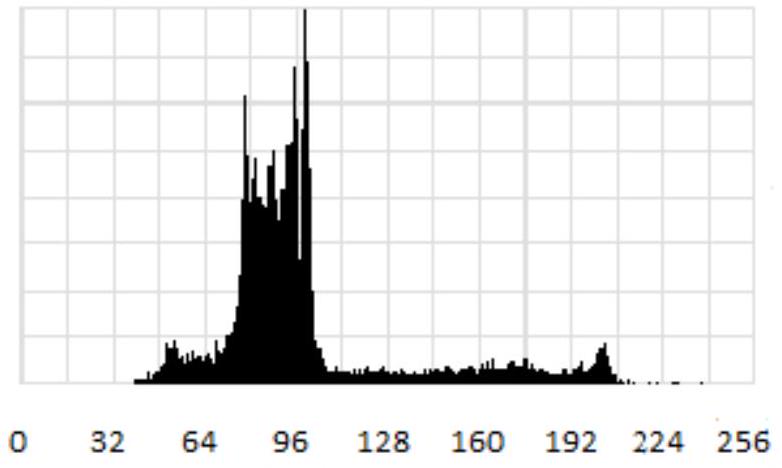 |
| :--- | :--- |
| Рисунок 4.3.3 - Зона интереса со сложным объектом | Рисунок 4.3.4 - Гистограмма зоны интереса со сложным объектом |
Случай, когда сложными являются одновременно объект и фон представлен на рисунках 4.3.5 и 4.3.6. В изображении объекта можно выделить, как минимум, два фрагмента, амплитуды которых отличаются разными средними значениями. Это пиксели лобового стекла и пиксели металлического кузова. Пиксели, образующие фон, делятся на две разные по величине части. Средняя амплитуда оказавшихся в тени пикселей, значительно ниже средней амплитуды пикселей остальной, большой части фона. Однако средняя амплитуда оказавшихся в тени пикселей близка к средней амплитуде кузова. Это обстоятель-
ство усложняет сегментацию. На гистограмме зоны интереса два явны локальных максимума. Что больше соответствует простой зоне интереса.
К сожалению, фактическое количество присутствующих на гистограмме локальных максимумов оказывается, как правило, значительно больше числа объектов в зоне интереса. Это подтверждают приведенные выше гистограммы. Поэтому вначале придется научиться отличать максимумы, вызванные случайными изменениями амплитуд (они будут называться ложными), от максимумов, соответствующих простым объектам из зоны интереса. Эти максимумы будут называться значимыми. Для этого требуется уточнить определение локального максимума гистограммы.
Рисунок 4.3.5 - Зона интереса со сложными объектом и фоном
Рисунок 4.3.6 - Гистограмма зоны интереса со сложыми объектом и фоном
https://cdn.mathpix.com/cropped/eb530be6-5346-4fc5-8ad9-46eb76334cd8-78.jpg?height=392&width=396&top_left_y=893&top_left_x=471 https://cdn.mathpix.com/cropped/eb530be6-5346-4fc5-8ad9-46eb76334cd8-78.jpg?height=451&width=785&top_left_y=837&top_left_x=1112
Рисунок 4.3.5 - Зона интереса со сложными объектом и фоном Рисунок 4.3.6 - Гистограмма зоны интереса со сложыми объектом и фоном|  | 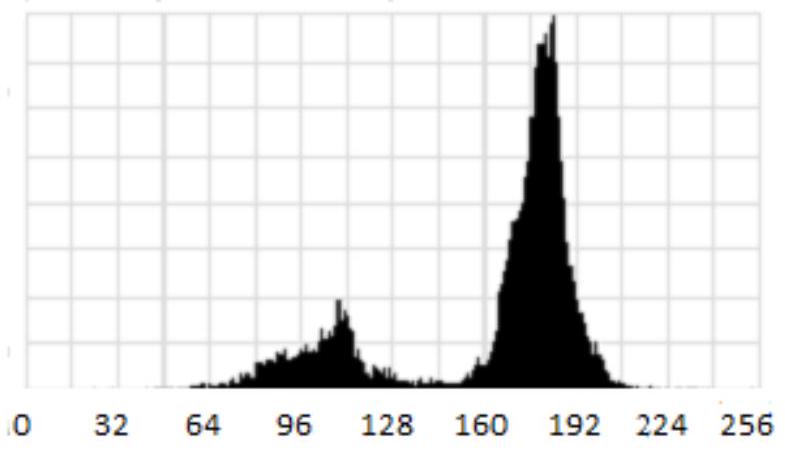 |
| :--- | :--- |
| Рисунок 4.3.5 - Зона интереса со сложными объектом и фоном | Рисунок 4.3.6 - Гистограмма зоны интереса со сложыми объектом и фоном |
Будем называть амплитуду j in Yj \in Y точкой локального максимума, а соответствующую ей повторяемость n_(j)n_{j} локальным максимумом, если выполняются следующие два условия. Во-первых, слева и справа от jj присутствуют амплитуды ii с повторяемостью n_(i)n_{i} и амплитуда ll с повторяемость n_(l)n_{l} такие, что n_(i) < n_(j)n_{i}<n_{j} и n_(l) < n_(j)n_{l}<n_{j}. Во-вторых, для всех амплитуд k,i < k < jk, i<k<j, и всех амплитуд s,j < s < ls, j<s<l, (если такие найдутся) выполняется равенство n_(k)=n_(j)=n_(l)n_{k}=n_{j}=n_{l}. Пусть x_(min)x_{\min } и x_(max)x_{\max } - минимальная и максимальная амплитуды на изображении x_(Q)x_{Q}. Будем называть амплитуду x_(min)x_{\min } также точкой локального максимума, если, вопервых, справа от нее присутствует амплитуда ll такая, что n_(l) < n_(x_(min))n_{l}<n_{x_{\min }}. Во-вторых, для всех s,x_("min ") < s < ls, x_{\text {min }}<s<l, выполняется n_(x_("min "))=n_(s)n_{x_{\text {min }}}=n_{s}. По этой же причине будем называть x_(max)x_{\max } точкой локального максимума, если слева от нее найдется амплитуда ii с повторяемостью n_(i)n_{i} такая, что n_(i) < n_(x_(max))n_{i}<n_{x_{\max }} и если для всех kk, i < k < n_(x_(max))i<k<n_{x_{\max }}, выполняется n_(x_(max))=n_(k)n_{x_{\max }}=n_{k}.
Разделение локальных максимумов на ложные и значимые предлагается выполнять с помощью методов математической статистики. Вначале для каждого локального максимума требуется определить ближайшие к нему левую x_(L)x_{L} и правую x_(R)x_{R} точки локальных минимумов. Затем следует выбрать уровень значимсти alpha\alpha и проверить гипотезу о том, что распределение амплитуд на ин-
тервале [x_(L),x_(R)]\left[x_{L}, x_{R}\right] является равномерным. В случае принятия гипотезы локальный максимум на интервале [x_(L),x_(R)]\left[x_{L}, x_{R}\right] считается ложным. В противном случае - значимым на уровне alpha\alpha. Проверка этой гипотезы подробно изложена в п. 1.8.
При проверке гипотезы требуется соблюдать следующие условия [xx]. Во-первых, для повторяемости n_(j)n_{j} каждой амплитуды x_(L) <= j <= x_(R)x_{L} \leq j \leq x_{R} должно выполняться неравенство n_(j) >= n_(min)n_{j} \geq n_{\min }. В случае использования критерия chi^(2)n_("min ")=5\chi^{2} n_{\text {min }}=5. Во-вторых, сумма повторяемостей n_(j)n_{j} амплитуд, x_(L) <= j <= x_(R)x_{L} \leq j \leq x_{R}, не должна быть меньше 50.
Если для исходной гистограммы указанные условия не выполняются, то ее можно изменить
Пусть n_(y)n_{y} - количество пикселей зоны интереса со значением y in Yy \in Y, называемое повторяемостью этого значения, а
на NN непересекающихся подинтервалов [a_(j),a_(j+1)[,1 <= j < N:}\left[a_{j}, a_{j+1}\left[, 1 \leq j<N\right.\right., и [a_(N),a_(N+1)]\left[a_{N}, a_{N+1}\right] таким образом, чтобы количество n_(j)n_{j} амплитуд, оказавшихся в каждом подинтервал [a_(j),a_(j+1)[:}\left[a_{j}, a_{j+1}\left[\right.\right., составляло не менее n_("min ")n_{\text {min }} значений. Величина n_("min ")n_{\text {min }} зависит от проверяемой гипотезы и применяемого критерия значимости. В рассматриваемом случае должно выполняться неравенство n_("min ") >= 5n_{\text {min }} \geq 5. Назовем точкой локального максимума подинтервал [a_(j),a_(j+1)[:}\left[a_{j}, a_{j+1}\left[\right.\right., содержащий n_(j)n_{j} значений, для которого выполняются следующие два условия. Во-первых, слева от него существует подинтервал [a_(i),a_(i+1)[:}\left[a_{i}, a_{i+1}\left[\right.\right. такой, что n_(i) < n_(j)n_{i}<n_{j}. При этом для всех подинтервалов [a_(k),a_(k+1)[:}\left[a_{k}, a_{k+1}\left[\right.\right. с номерами i < k < ji<k<j выполняется равенство n_(k)=n_(j)n_{k}=n_{j}. Во-вторых, справа от [a_(j),a_(j+1)[:}\left[a_{j}, a_{j+1}\left[\right.\right. существует подинтервал [a_(l),a_(l+1)[:}\left[a_{l}, a_{l+1}\left[\right.\right. такой, что n_(l) < n_(j)n_{l}<n_{j}. Для всех подинтервалов [a_(s),a_(s+1)[:}\left[a_{s}, a_{s+1}[\right. с номерами j < s < lj<s<l выполняется равенство n_(s)=n_(j)n_{s}=n_{j}. Подинтервал [a_(j),a_(j+1)[:}\left[a_{j}, a_{j+1}[\right. будет называться локальным максимумом на уровне значимости alpha\alpha, если на этом уровне отклоняется гипотеза о равномерном распределении амплитуд на интервале [a_(i),a_(l+1)[:}\left[a_{i}, a_{l+1}[\right..
*/






























